[SIGIR'23] PersonalTM: Transformer Memory for Personalized Retrieval
Summary
- DSI 대비 (BM25, precision, MRR) 성능 향상. 구조적으로 user profile, context 정보 잘 융합.
- decoding stage에서 hierarchical loss 도입(semantic hierarchical document id assignment 효과가 있다고 함).
- 부가요소로 flexible adaptor strategy(prefix adapter)를 통해 index update의 scalability와 computation costs 향상.
파악해야할 Research Question
- 어떻게 융합? 구조가 어떻게 되는가?
- hierarchical loss란 무엇이고, 왜 semantic hierarchical document id assignment효과가 있나?
- prefix adapter란 무엇이고 왜 index update가 좋아지나?
논문에 대한 견해
3가지 시사점이 있음.
- query랑 history를 분리하여 각 모듈로써 사용함. 특히, query랑 관련있는 history만 가져왔는데, 이게 큰 효과가 있었음.
- hierarchical loss를 도입하였는데 document _id를 의미적으로 구분짓도록 클러스터링 해주고, 이를 이용한다는 측면에서 Interpretability가 증가하고 성능 gain도 일부 있었음. 또, 모든 document에 대한 embedding 관리를 하지 않아서 시스템적인 부담도 줄어들것 같음.
- Prefix tuning 기반의 Prefix adapter, 즉 작은 사이즈의 learning embedding만 업데이트에 사용하여 시스템적으로 업데이트 시간과 부담을 낮춤.
그리고, 데이터 셋 AOL4PS 이 네이버 검색 로그와 상당히 유사함. zero-shot task도 평가해 볼 수 있어서 오픈데이터 벤치마킹 해봐도 좋을 듯
Architecture
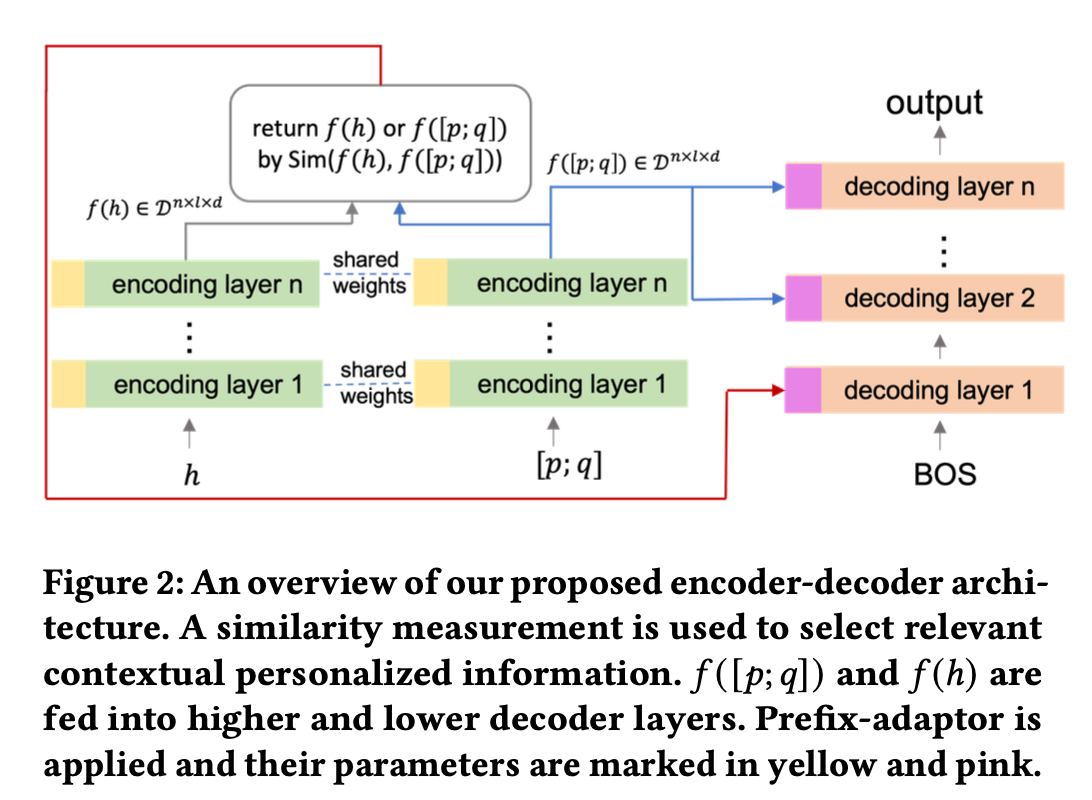
-
user profile과 context 어떻게 융합?
-
일단 q(query)와 h(context) 분리 (input length limitation 때문이라는데, 아직 잘 모르겠음)
-
q 와 d(click document) 사이 connection을 더 잘 배울 수 있도록 two similarity measurement 도입
-
hueristic: Relevance denoise for personal context 측면에서 query에 대해 관련성이 큰 history만 필터링 하여 h만듦. (디폴트값은 가장 최근 clicked document)

-
prefix adapter란, encoder(yellow)와 decoder(pink)쪽에 prefix-tuning 기법을 써서, 빠른 임베딩 업데이트를 유도하는 방법. (대부분 학습 파라미터는 prohibitively large for retraining), prefix length 는 5.
Loss 측면
Hierarchical loss motivation: document id를 디코딩하는건 accummulated error가 존재한다는 데?.. 무슨말인지 잘모르곘네
decoding the document id by digit has problem of accumulated errors.
어찌되었든 semantic clustering 관점에서 document id의 비트가 앞쪽에 가까울수록 중요하고, 뒤쪽에 가까울수록 덜 중요하다는걸 반영하고자 함.
document_id가 카테고리 아이디 의미처럼 [대카테고리;중카테로고리;소카테고리] 이런식의 의미로 doument_id가 mapping되어야 하는것 같음.

Experiment 파트를 보면 sementic clustering 방법중 fast-pytorch-kmeans 를 써서 document들을 10개의 cluster로 그룹화하고 document_id길이를 6으로 하였다고 함. 𝑤1 is 3/6, 𝑤2 is 2/6, 𝑤3 is 1/6을 사용.
Dataset
AOL4PS
382,222 개의 query 와 user click history로 이뤄진 데이터셋. query 중 train에 등장하지 않은 19,957 개의 query가 있으니 zero-shot task도 해볼 수 있음.
Experiment
T5 가 backbone model로 사용됨.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement De- 550 langue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, 551 et al. 2019. Huggingface’s transformers: State-of-the-art natural language pro-
cessing. arXiv preprint arXiv:1910.03771 (2019)
단순 BM25보다 differentiable encoder 계열 검색 성능이 크게 높음.
논문에서 제안된 방법들이 일관되게 성능 gain들이 있지만, Relevance denoise for personal context 방법에서 성능 gain이 가장 큼
