GPT 연구 흐름에 집중한다.
LLM Review Part 1
가장 먼저 GPT 모델을 리뷰해본다.
Why GPT?
LLM 의 발전을 잘 보여주는 그림. 2018 이후 LLM 계열 논문이 폭발적으로 증가. 특히 대중의 관심을 ChatGPT(GPT3.5) 부터 Business적으로 도약하게된 계기가 됨. GPT가 LLM의 부흥기를 이끌었기 때문에 Seed 논문인 GPT계열 모델군들을 이해하는것이 필수적임.

From LLMPracticalGuide:
https://github.com/Mooler0410/LLMsPracticalGuide
한국어 초간단 설명 YouTube: https://youtu.be/XwlLeVhWCCc?si=7C9s8r546w84hdqw
Why Lamma?
다음과 같이 오픈소스로 공개된 LLaMA 계열 모델이 가장 많이 변형되어 사용되므로 GPT모델을 모두 리뷰하고, LLaMA 모델로 넘어가서 리뷰도 해야함.

GPT 리뷰
GPT-4까지의 LLM survey 논문: https://arxiv.org/pdf/2402.06196
- [GPT-1, 2018] Improving language understanding by generative pre-training, OpenAI, A. Radford et al
- [GPT-2, 2019] Language models are unsupervised multitask learners, OpenAI, A. Radford et al
- [GPT-3, 2020] Language models are few-shot learners, OpenAI, T. Brown et al
- [GPT-4, 2024] GPT-4 Technical Report, OpenAI
한글로 설명한 YouTube 링크가 있으면 먼저 발표를 듣고, 논문을 보는게 이해가 빠름.
우선, 인터넷에 정리된 문서를 통해 빠르게 이해하고, Motivation, Contribution, Detail로 정리.
GPT-1: Improving Language Understanding by Generative Pre-Training
YouTube: https://youtu.be/4qv_ofZN5_U?si=fJhyh94Y3-QxZP-V
Motivation
labeled data가 희소하기 때문에, 풍부한 unlabeled text corpus 를 이용하고 싶은 니즈가 있음. two-stage training 을 통해 여러 task에 trasnfer 가능한 task agnostic model 을 만들 수있는가에 대한 연구. 이는 pre-training 단계에서 얻은 general한 representation power를 fine-tuning단계에서 활용하여 더욱 높은 성능을 만들 수 있도록 하기 위함임.
Contribution
- Pre-training: 큰 텍스트 데이터셋을 사용하여 비지도 학습을 통해 언어 모델을 사전 학습.
- Fine-tuning: 사전 학습된 모델을 특정 태스크에 맞게 미세 조정.
- 결과: 다양한 NLP 태스크에서 기존의 지도 학습 모델을 능가하는 성능을 보여줌.
Detail
two-stage training을 한다. 첫번째로 large dataset으로 unsupervised로 generative task에 대해 pre-training을 한다. 그 후, 적은 labeled data로 discriminative task에 대해 fine-tuning을 한다. GPT는 auto-regressive 계열 모델을 사용함. 모델은 multi-layer Transformer decoder 를 사용 하였음.
Unsupervised Pre-training
Large corpus를 unsupervised로 학습하게됨. corpus내의 next token을 맞추기 때문에 label을 corpus만 있으면 얻을 수 있음.

Supervised Fine-tuning
label이 있는 여러 task에 다음과 같은 방식으로 fine-tuning 학습을 진행. task마다 주어진 label $y$를 예측할 수 있도록 모델 끝단에 마지막 layer 인 $W_y$ 를 추가 함. $W_y$는 fine-tuning할 task마다 다르게 설정됨. supervised model의 generalization 향상과 수렴 가속화를 위해 auxiliary objective를 $L_1$을 추가하여 최종적으로는 다음 objective $L_3$를 최적화한다.

주어진 Fine-tuning task 마다 다음과 같이 input과 linear layer가 달라짐. 대표적으로 4가지 task가 있음.
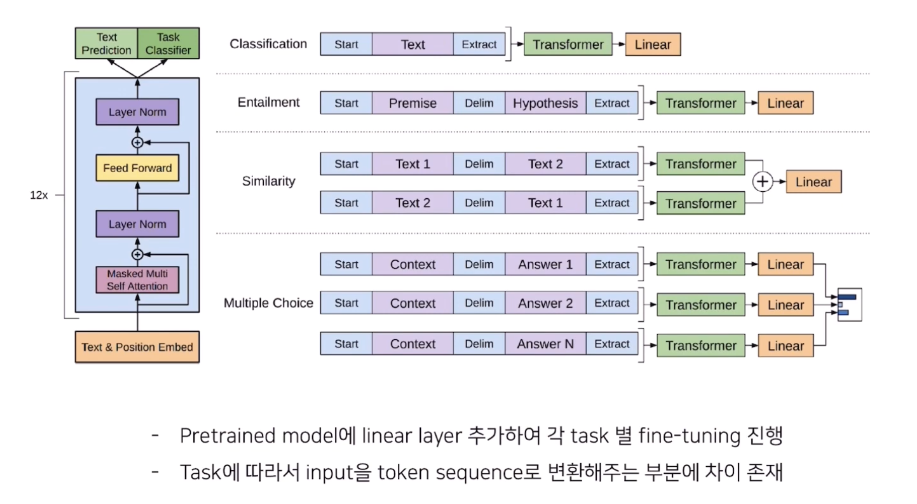
생소할 수 있어서 좀더 설명하면, classification을 제외한 다른 3개의 task는 두 문장들 사이의 관계를 맞추는 task임. 전체 task를 간략히 설명하면 다음과 같음.
- Entailment: 문장 A와 문장 B사이의 관계를 Contradiction, Neutral, Entailment 의 3가지 분류로 나뉨.
- Similarity: 두 문장 사이의 유사도 계산.
- Multiple Choise: Q&A task.
- Classification: 데이터셋에 따라 두가지 Task가 있음.
- CoLA dataset: 문법적으로 맞았는지 틀렸는지 분류.
- SST dataset: 문장의 sentiment 분류.
Experiment
데이터 별 task 는 다음과 같음.
- Classification: CoLA, SST2
- Similrity: MRPR, STSB, QQP
- Entailment: MNLI, QNLI
- Multiple: RTR
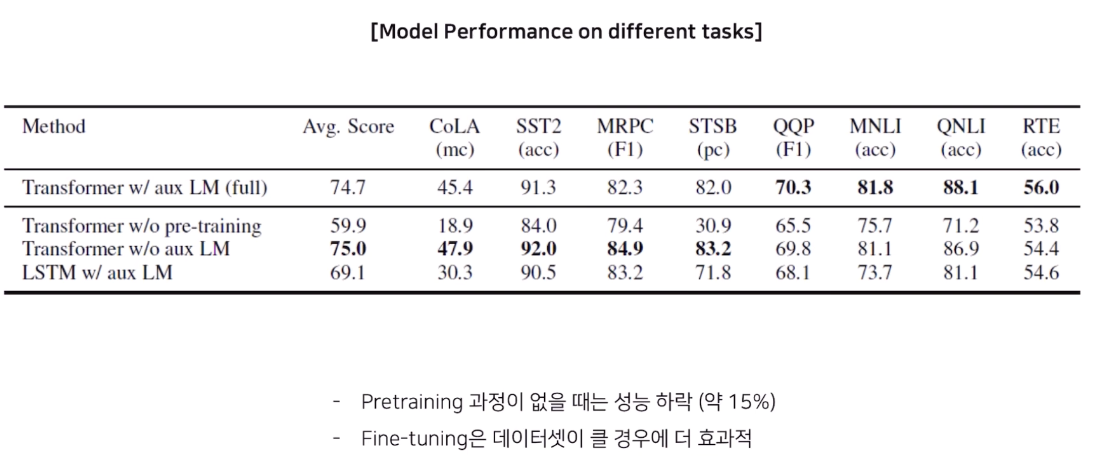
주목할 점은 full (transformer사용, fine-tuning) 에서 전반적인 성능 향상이 가장 좋았음. 놀라운점은 fine-tuning없는 transformer w/o aux LM모델이 Classification과 Similarity task에서 더 높은 성능을 보였다는 점. 그런데, 뒤쪽 데이터 셋(CoLA -> RTE)으로 갈수록 (fine-tuning에 활용하는) labeled 데이터 사이즈가 크기 때문이라고 함.
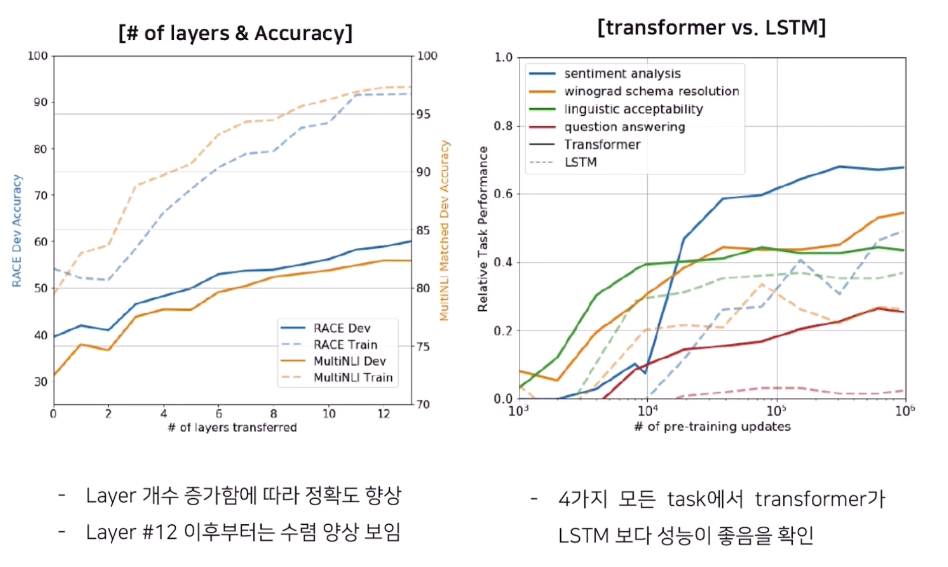
또한, 모델 Capacity가 클수록 더 성능이 좋다는 점을 Analysis 파트에 리포트함. 왼쪽 그래프를 보면 layer가 커질 수록 성능이 더 좋아지며, Transformer 모델이 LSTM 보다 전반적으로 성능이 좋았던 것을 확인.
GPT-2: Language Models are Unsupervised Multitask Learners
YouTube: https://youtu.be/8hd2Q-3-BsQ?si=Mt0bc_Vv9b47lII2
Motivation
GPT-1에서 new dataset, 즉 새로운 task에 대해 fine-tuning이 필수적으로 필요함. GPT-1대비 더 큰 대용량의 데이터로 fine-tuning없이 zero-shot이 가능한 모델을 만들 수 있을지에 대한 연구.
Contribution
- 모델 크기 증가: 15억 개(GPT-1 대비 10배 이상)의 파라미터를 가진 모델을 도입하여 더 복잡한 패턴을 학습할 수 있도록 함.
- 데이터 셋 크기 증가: 800만개 이상의 문서를 포함한 40GB WebText 데이터 셋 사용. 문서 질에 초점을 맞춰 생성함.
- Zero-shot, One-shot, Few-shot 학습: 별도의 task별 학습 없이도 새로운 태스크에 대응할 수 있는 능력을 보임.
- 결과: 다양한 NLP 태스크에서 state-of-the-art 성능을 달성함. 이는 대용량 모델들이 명시적인 supervison없이도 더 더양한 task를 수행하는 방법을 학습하기 시작했다는 것을 암시.
Usage
https://huggingface.co/openai-community/gpt2에 올라온 것을 보면, Task를 입력으로 다음과 같이 사용할 수 있음.
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]물론, sentence embedding 역시도 이렇게 뽑아올 수 있음(pytorch 기준으로 설명).
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)Detail
GPT-2에서는 input 말고도 어떤 task인지에 대한 정보도 모델에게 넘겨줌으로써, fine-tuning없이 zero-shot으로 output을 만들 수있도록 모델을 설계함.

Tokenizer
Byte-level의 Byte Pair Encoding, BPE 방식을 사용하여 vocabulary 사이즈를 GPT 대비 크게 줄임. 256 size가 됨.
Model Size
GPT-2 SMALL 이 GPT, GPT-2 MEDIUM이 BERT LARGE와 비슷한 사이즈 임. 또 Implementation Detail인데 Transformer의 Layer Normalization이 성능에 좀 큰 역할을 했다고 함.

Experiment
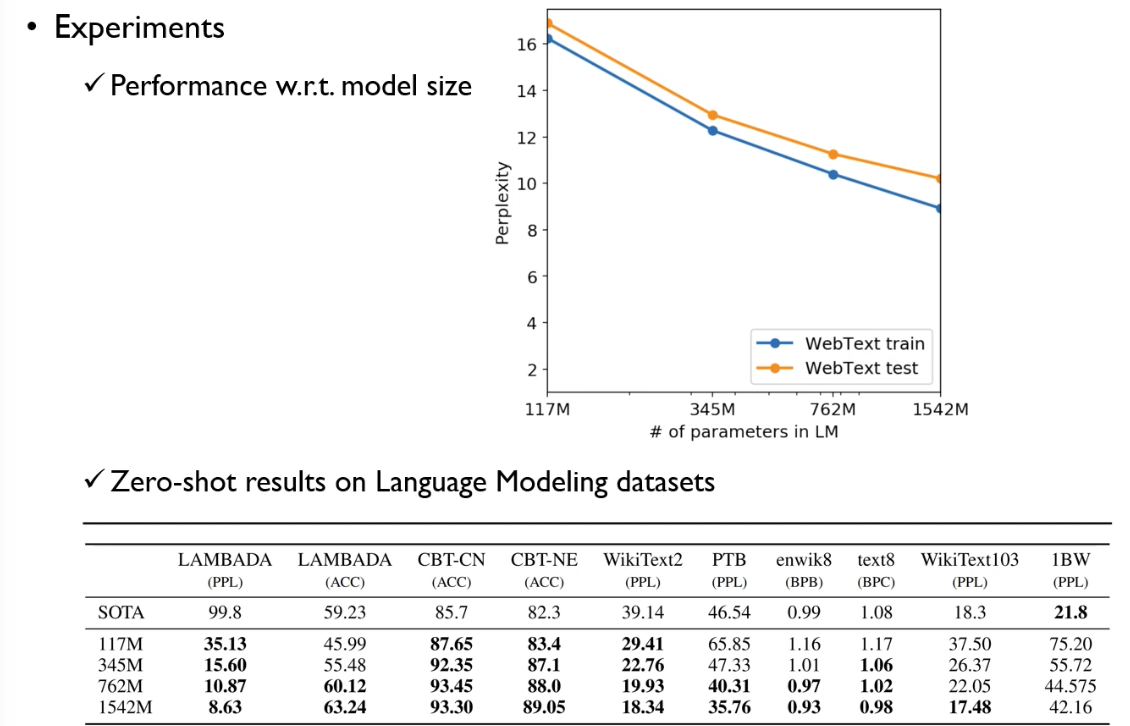
PPL(Perplexity)는 낮을 수록 좋은 값. Model parameter가 많아질 수록 PPL이 좋아짐.
또한, 8가지 Downstream task에 대해 zero-shot 결과를 보았을때 model paramater가 많아질수록 성능이 좋아짐. 즉, GPT-2 에서 학습된 token 별 embedding의 퀄리티가 zero-shot task까지도 가능할 정도로 generalization이 잘 되어있는 임베딩이라는 뜻.
GPT-3: Language Models are Few-Shot Learners
YouTube: https://youtu.be/xNdp3_Zrr8Q?si=86nyOhrgQW5UuXeU
Motivation
GPT-2구조는 모델 구조 상 task-agnostic 특징이 있어서 여전히 fine-tuning을 해야 높은 성능을 달성할 수 있다는 한계가 있고, 모델 구조가 커짐대비 fine-tuning할 데이터가 부족할 경우 spurious correlation이 발생할 수 있다는 점을 주장하였음. fine-tuning을 위한 labeled 데이터를 얻는것은 어려우며, 인간은 몇개의 example 만으로 특정 task를 수행할 수 있는 능력을 가지고 있음을 지적 함. Meta-learning을 LLM을 통해 학습시킴으로써 하나의 거대 모델안에 다양한 task 로 부터 얻은 unified된 knowlege가 representation에 녹아들어, 몇개의 예제만으로 어떤 task를 잘 수행하며 dataset에 없는 심지어 새로운 task도 수행할 수 있는 인간에 가까운 능력을 보일 수 있을지에 대한 연구.
Contribution
- 모델 크기 극대화: 1750억 개(GPT-2대비 10배이상)의 파라미터를 가진 모델을 통해 이전 모델들보다 훨씬 복잡한 언어 패턴을 학습.
- Few-shot Learning: 최소한의 예제만으로도 높은 성능을 발휘할 수 있는 능력을 보여줌.
- 결과: 다양한 언어 task에서 GPT-2를 넘어서는 성능을 입증.
Detail
다음과 같이 Meta-learning 방식으로 데이터셋을 구성함. 한 example(sequnce)이 어느 한 task에 대한 dataset이 되어 in-context learning을 함. outer loop의 파라미터로 inner loop의 파라미터를 최적화함.
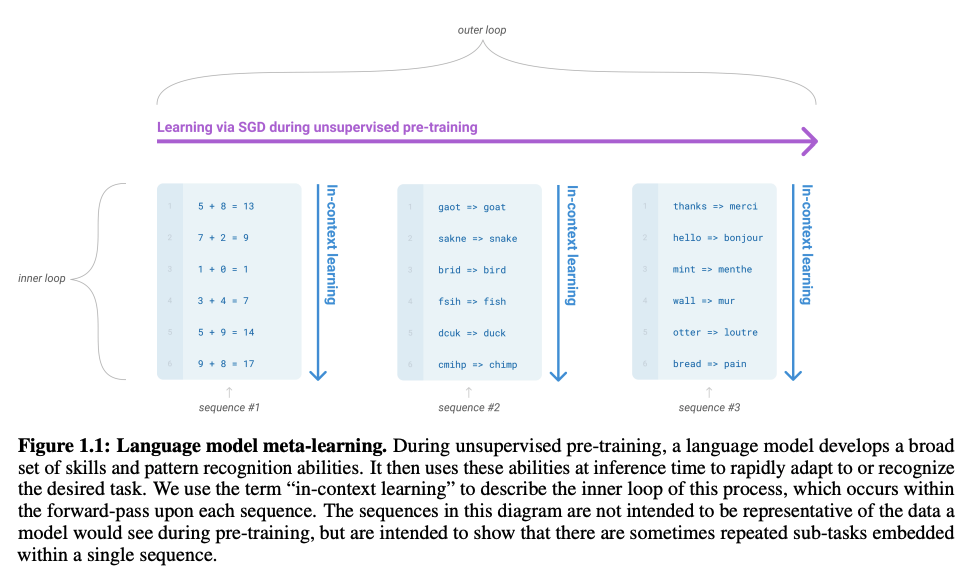
메타러닝은 일반적으로 데이터 하나가 task를 의미하는데, 다음과 같이 inner-level과 outer-level의 학습이 반복되는 bi-optimization 프로세스를 갖는 특징이 있음. outer-level에서 모든 데이터들(tasks)들을 잘 풀수 있는 meta-parameter $\theta$ 를 학습하는걸 주목하자.
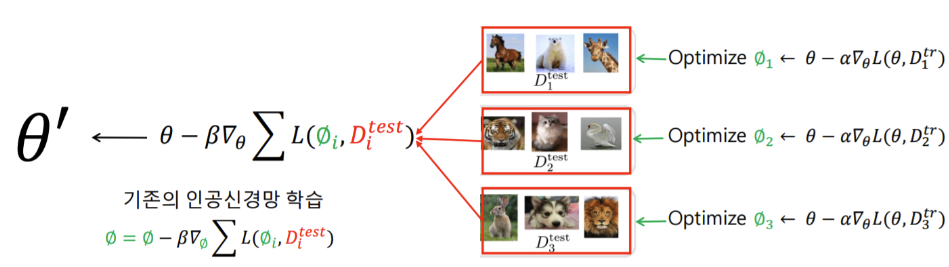
다음과 같이 GPT-3에서는 k-shot 에 대해서는 오른쪽 그림의 fine-tuning과는 다르게 gradient update를 하지 않는 다는 사실을 강조. translation task에 대한 하나의 seqeunce 를 모델의 input으로 줄때, seqeunce에서 task description을 제외한 token수(demonstration)를 더 넣어줌으로써 k-shot 이 가능해짐. GPT-3에서 token수, 즉 context length는 2048까지 가능함 (transformer구조 상 제약이 있음).

Approach
다음과 같이 GPT-3에서는 FT 와 FS 에 대한 방법을 모두 적용하였는데 장단점을 다음과 같이 정리하였음. FT의 경우 benchmark성능은 잘나올 수는 있지만 OOD문제가 있고, generalization능력이 떨어진 다는점이 있고, FS의 경우 학습이 필요치않고, 몇개의 demonstration만으로도 납득할만한 성능은 낼 수 있지만, 여전히 hard한 task에 대해서는 benchmark 성능이 FT대비 떨어질 수 있다고 주장.

Model Size
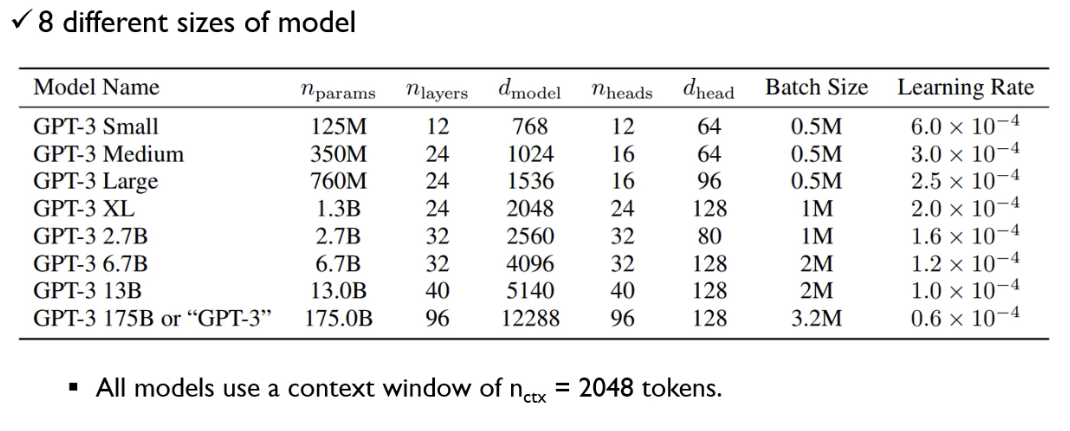
다음과 같이 GPT-3의 모델사이즈는 8개의 버전이 있으며 가장 큰 모델의 경우 GPT-2 대비 10배 이상임.
Training Dataset
3가지정도의 전처리를 통해 high-quality 의 데이터셋을 만들었으며, train과 validation 사이의 중복된 데이터는 삭제했다고 함. 그런데 논문에서 실수로 중복이 생기는 버그가 발생했지만 재학습을 위한 천문학적인 비용을 감당하지 못해 그냥 사용했다고 함(약 50억 정도 드는것으로 추정 됨).
Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model

데이터 사이즈가 워낙 방대하기 때문에 전체 데이터를 한 epoch 도 사용하지 못하는 상황이 있음.
Experiment
GPT-1부터 꾸준히 주장하는 내용. 다음과 같이 모델 파라미터가 커질수록 선형적으로 task가 어떻든 평균적으로 성능이 증가하는 경향이 있음. 또한, k-shot 에서 demonstration example을 더 줄 수록 성능이 올라감.
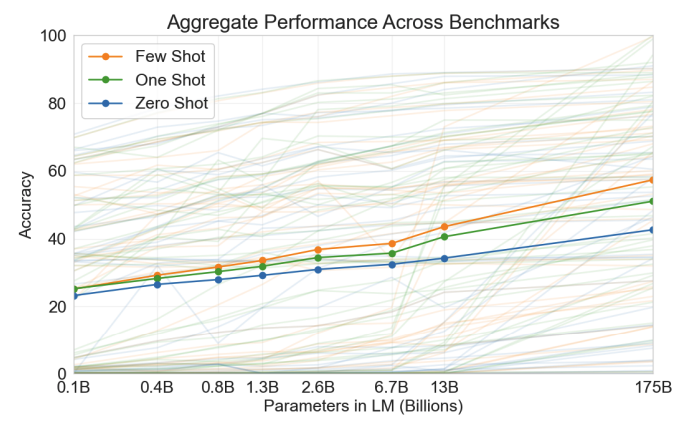
이 외에도 실험이 많지만 여기까지만 리뷰하도록 함.
GPT-4 Technical Report
YouTube: https://youtu.be/u0DfGEnM9Cc?si=5-EcXVAFDt5frBV1
3년만에 GPT가 돌아 옴. 서비스적으로 크게 향상됨. OpenAI와 microsoft가 합작하여 발표한 논문. 기술적인 부분이 많이 공개되지는 않아서 아쉬움.
Motivation
GPT-3에서 보여준 성과를 기반으로, 더 복잡하고 다양한 언어 태스크를 처리할 수 있는 모델을 개발하고자 함. 특히, 다중 모달 입력(텍스트, 이미지 등)을 처리할 수 있는 능력을 갖추는 것이 목표.
Contribution
- 멀티모달 학습: 텍스트와 이미지를 동시에 처리하여 복합적인 태스크를 해결할 수 있는 능력.
- 모델 최적화: 기존의 GPT-3보다 더 효율적이고 강력한 성능을 발휘할 수 있도록 모델 구조와 학습 방법을 최적화.
- 결과: 다양한 멀티모달 태스크에서 높은 성능을 발휘하며, 인간 수준의 언어 이해와 생성을 입증.
Detail
100 page가 넘는 분량이기 때문에 YouTube를 보고 기억할 부분만 적음.
Reinforcement Learning from Human Feedback, RLHF
사람이 주는 피드백으로 언어모델을 최적화 하는 기법이 적용되었다고 함.
InstructGPT: Training language models to follow instructions with human feedback 논문을 읽어봐야 자세히 알 수 있음.
kakao enterprise에서 정리한 Tech 블로그글을 읽어봐도 좋음.
Visual Inputs
propmt로 image 와 text를 받을 수 있도록 함. 기술적으로 자세히 공개되진 않았지만 이미지와 텍스트를 함께 이해하고 있는 것으로 보임.
Capabilities(Experiment)
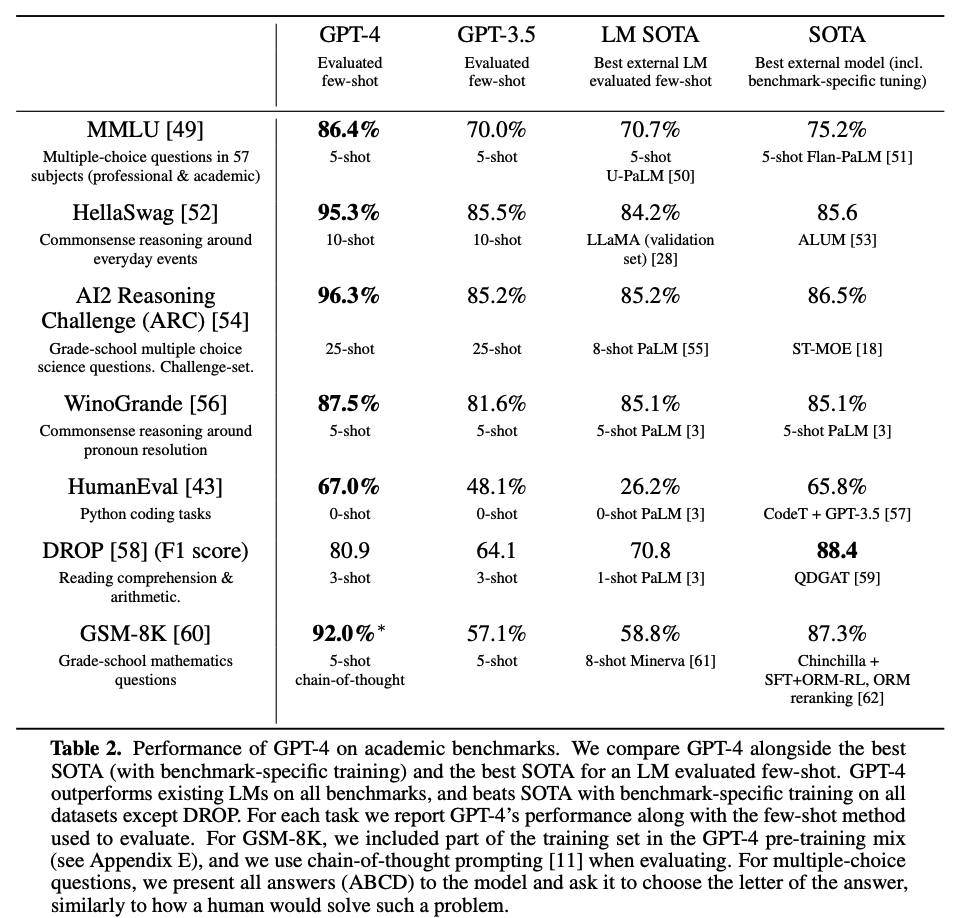
인간을 위해 디자인된 exam들에 대해 놀라운 성과를 냄. 특히 변호사 시험의 경우 상위 10%의 기록을 냄. GPT-3.5가 하위 10%였던 반면, GPT-4는 상위 10%에 해당할 정도로 급상승.
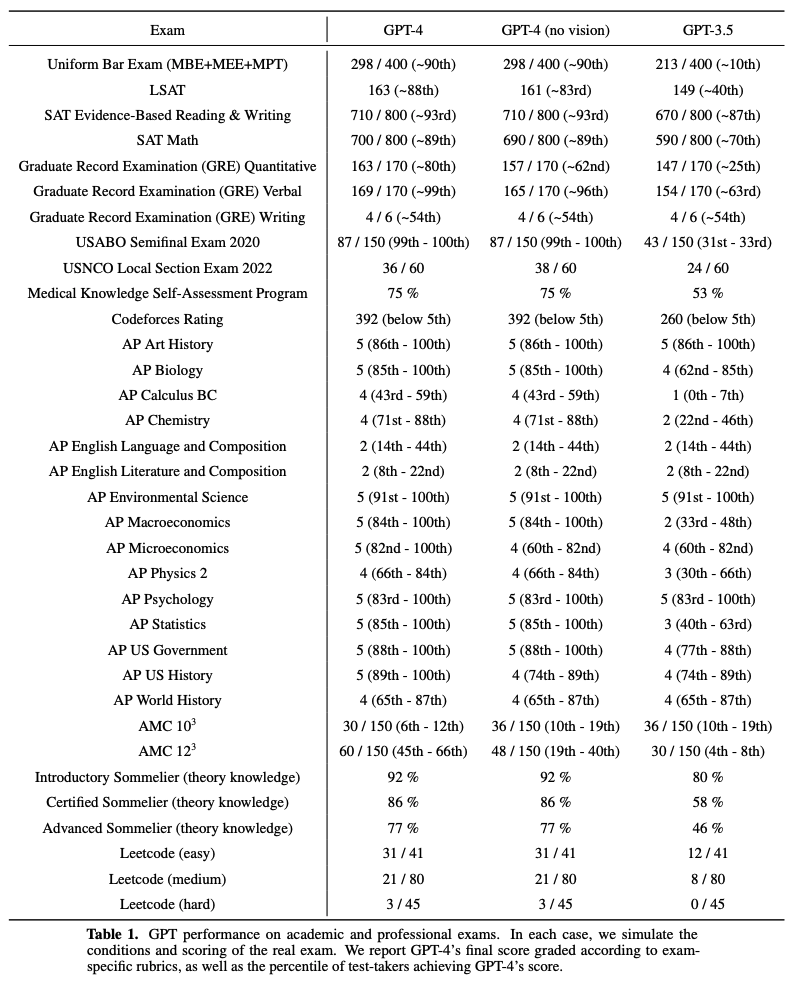
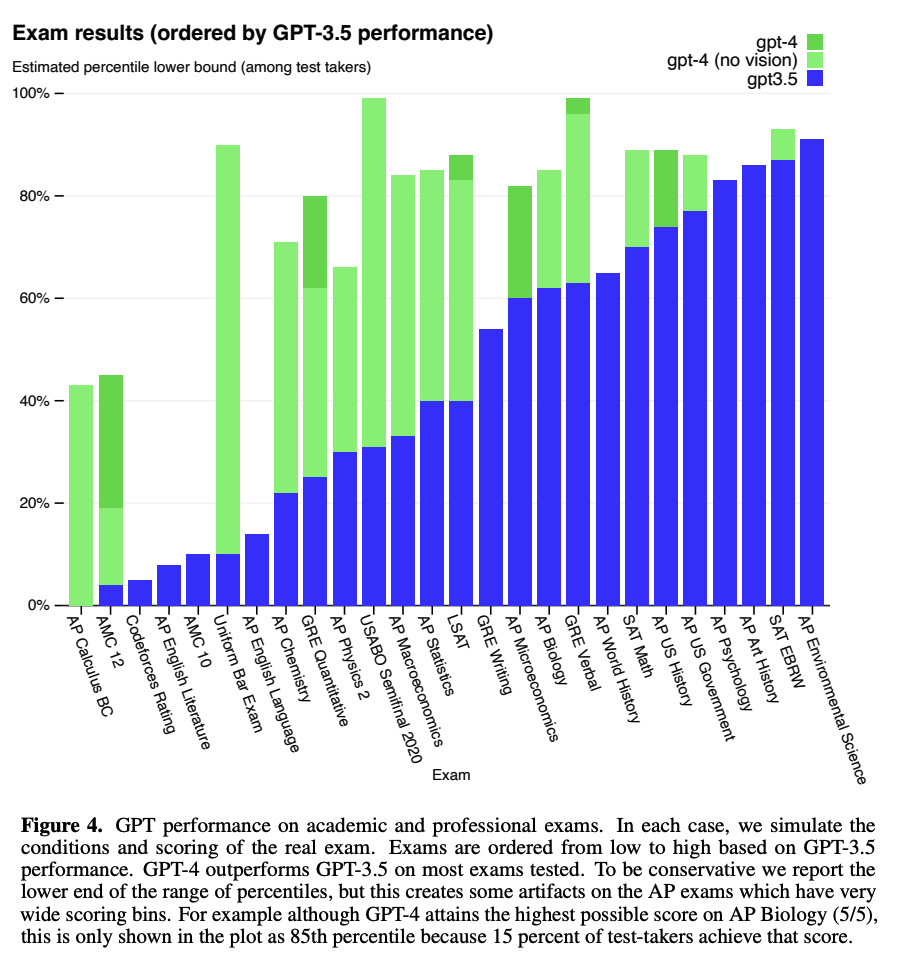
다음과 같이 다양한 Academic Benchmark들에 대해서도 대부분 SOTA를 달성