논문링크: https://arxiv.org/pdf/2104.08821
이미지에서는 ICML'20 에 발표된 SimCLR: A Simple Framework for Contrastive Learning of Visual Representations 방법이 Contrastive learning의 seed 논문이다.
Unsupervised 와 supervised setting 각각 다른 positive-pair 데이터 구성을 가지는 특징이 있음.
특히, Unsup 셋팅의 경우 Text에서 Contrastive learning 접근을 하고자한 SimCSE 논문이 SimCLR 대비 어려운 점은 positive pair를 구성할때, Visual 정보에서는 단순히 사진을 Rotation, Crop 등 만 해주어도 쉽게 얻을 수 있으나, Text 의 특징상 문맥이 이상해지거나 전혀 다른 의미가 되기 때문에 쉽지 않은 부분이 있다. 이런 어려움들을 잘 극복하도록 설계한 논문이라 생각하면 된다. 여기 발표를 보면 이해가 쉽다.
핵심내용
unsupervised
발표를 들어보면, Unsupervised setting에서 Postive pair를 만드는 방법은 input text는 그대로 주고, dropout mask를 두 입력 사이에 다르게 적용하자는 심플한 아이디어 라는걸 알 수 있음. (Negative pair는 다른 input text에 대해 in-batch negative sampling 수행)
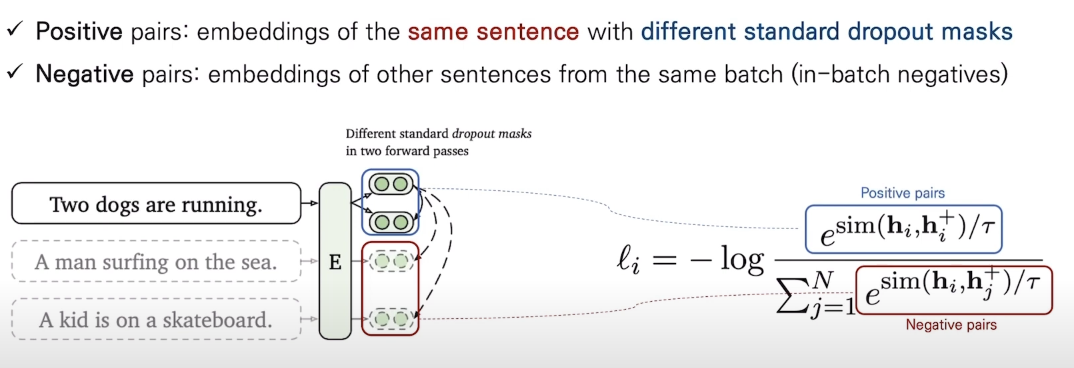
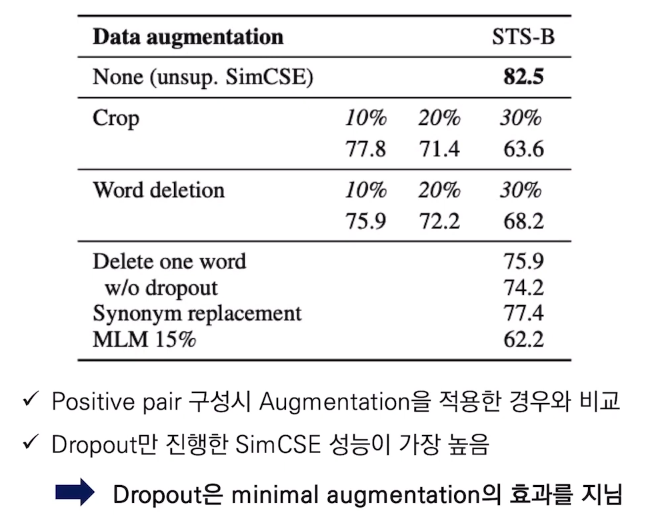
아래 STS-task 에 대한 실험 결과를 보면 위와 같이 (Unsup task에서) 단순히 input text에 아무 변형도 안하고 dropout 만 다르게 해주는게 Crop, Word deletion, Synonym replacement 등 복잡한 augmentation 과정을 한 것보다 더 성능이 좋았다는 것을 알 수 있다.
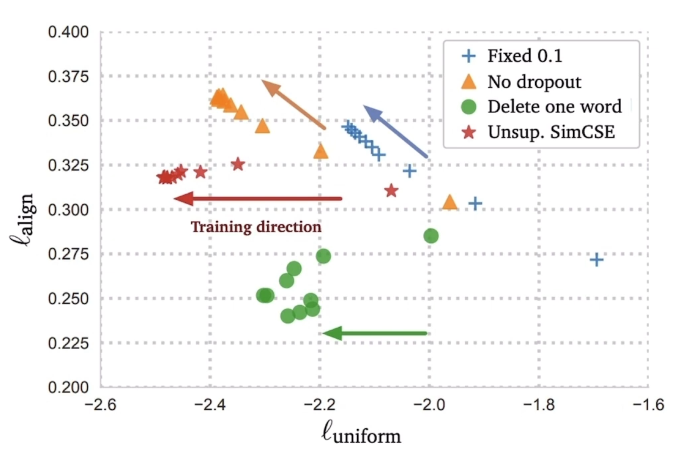
또한, embedding 성능의 정량적인 평가를 위해 alignment 와 uniformity(낮을 수록 좋음) 를 계산 해봤을때 dropout만 사용하는게 가장 좋다는것도 보임
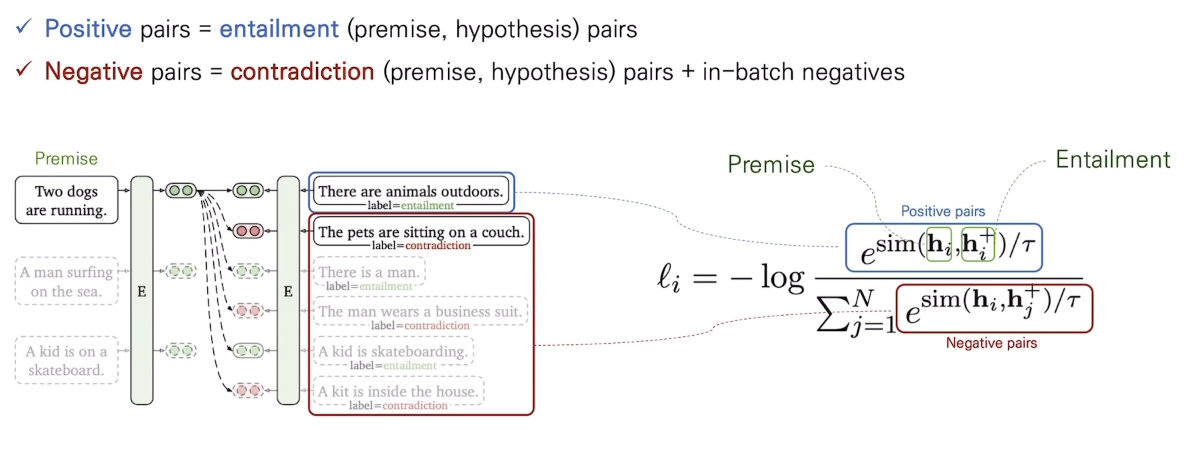
Supervised
supervised setting의 positive/negative pair는 NLI 데이터셋에서 premise 가 주어졌을때 entailment, contradiction, neutral 과 같은 label이 주어지는데 이를 활용해 다음과 같이 구성한다.