주어진 Session 에 대한 Representation 을 구할 때 유사한 session 이면 similarity가 높아지도록 만들고자하는 것은 자연스럽다는 것에 모두가 동의를 할 것이다.
그렇다면, SimCLR, SimCSE 같은 contrastive learning 방식을 추천 도메인에서 Sequential 모델에 어떻게 반영할지에 대한 연구를 찾는다면 이 논문이 하나의 예시로 생각 될 수 있을 것 같다.
아래 DSBA연구실의 유튜브 설명을 봐도 좋다.
SIGIR'21 에 게제된 CL4RS: Contrastive Learning for Sequential Recommendation 논문에 대한 핵심부를 정리해보자.
서두에 장단점을 정리해보면 다음과 같다.
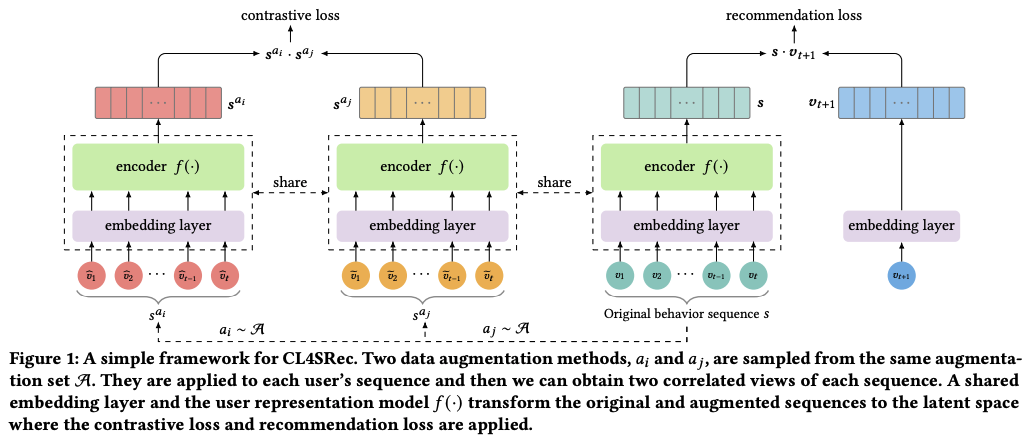
Architecture
CL4Rec은 모델 구조가 간단해 구현하기 쉽다. 하나의 augmentation 기법 기준 기존 sequence에서 샘플링을 2번 해줘서 augmented sequence 를 얻고 forward step 을 거친 뒤 마지막 interaction 에 대한 embedding으로 통해 contrastive loss를 계산한다. 샘플링이 2번 추가되고 forward step을 2번 더 해줘서 overhead가 생긴다는 점은 단점이다.
그리고, 논문을 보면 contrastive loss 계산은 다음과 같이 계산되며 코드는 matrix 형태로 계산됨. (diagnonal 원소들이 positive pair),.
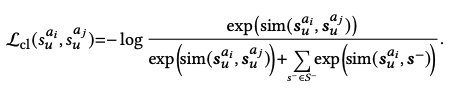
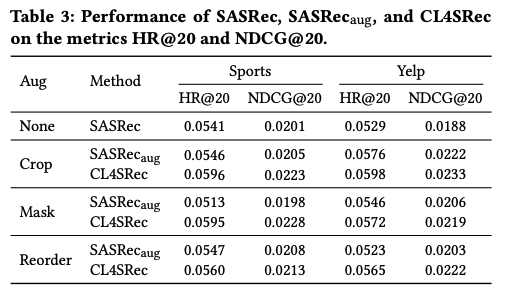
Experiments
논문에 공개된 각 augmentation 기법과 contrastive loss 에 대한 abalation study 성능표를 보면 일관된 성능 향상을 보여주는 편. 하지만 mask augmenation의 경우 contrastive loss term 없이 사용시 Sports에서 성능 하락이 있었음.
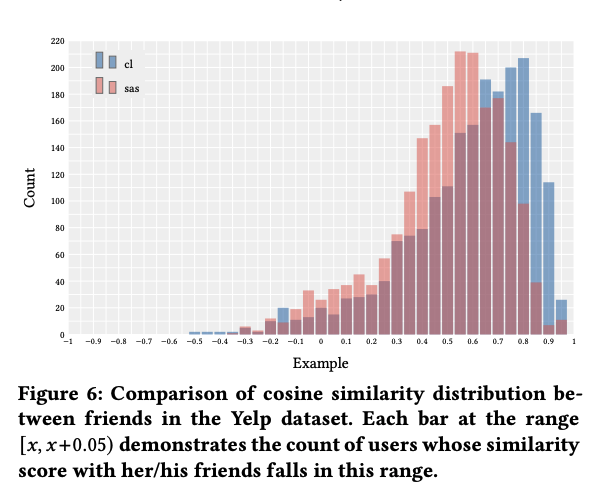
그리고, 실험 결과에서 다음과 같이 Yelp 데이터 셋에서 친구인 세션의 유사도가 Contrastive loss 를 도입하면서 더 가까워졌다는 것을 강조하고 있는데, 이렇게 정성적인 결과를 정략적으로 보여주는게 중요하다고 생각한다. 쇼핑 검색의 상황에 대입해 생각해보면, 같은 검색어 (여기선 친구)인 세션의 경우 contrastive loss를 도입하면 더 가까운 representation 이 될 수 있을 것 같다는 생각이 들었다.