검색 및 추천에 사용할 수 있는 Cold-start에 강한 Two-tower 모델을 제시한 논문이어서 리뷰해보았다.
[Arxiv'24] Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Summary
- Motivation: 유저 임베딩은 유저의 다양한 선호도를 포착하는데는 어려움이 있으며, 실시간성을 트래킹하는 것 역시 비용이 많이든다는 문제가 있음. 이런 문제들을 현업에서 다루는 방법을 제시한 논문
- 하나의 인코더로 2가지 relationship을 겨냥한 query와 target 총 3가지 타입의 임베딩을 뽑고(SIMO방식이라 칭함), 일간 배치로 추천에 활용함.
- 유저임베딩 대신 query embedding 으로 two-tower를 표현하였기 때문에, 모든 임베딩이 item-side로만 결정됨. 그리고, item embedding 역시 자연어 정보(카탈로그)만 있으면 embedding을 뽑아낼 수 있어서 cold-start에 취약점을 보완한 모델이 됨.
- contrastive learning 방식으로 query, target 임베딩을 같은 공간으로 맵핑하는 학습을 함. Negative 샘플을 바탕으로 Loss 계산시 softmax의 방향에 따라 두 타입의 Loss를 계산하여 합산함.
- 유저 profiles을 매 2분마다 업데이트 하면서 제공하는 방법 제시. 네덜란드와 벨기에의 서비스 Bol(개인화된 피드를 제공하는 서비스)에서 4.9% 성능 향상
Perspective
- catalog 정보로 부터 item embedding을 뽑기 때문에 cold start product에 효과적임
- view-buy, buy-buy relationship을 사용했는데, click도 활용하면 좋을것 같음
- 아직 Arxiv 단계라 신용성이 약간 떨어짐
Four Challenges in Personalized Feed Systems
Personalized feed systems 을 search engine 과 같이 바라보았고, 4가지 challenge가 있음을 규정함.
이들중 앞의 3개 challenge 에 집중.
- Customer representation challenge.
- dynamic interactions 에서 유저의 선호도를 찾는 문제
- 유저속성을 유저 임베딩에 어떻게 잘 녹여낼지에 대한 문제
- Item representation challenge
- 아이템 속성의 중요도가 상품마다 다름. 예를 들어 책에서는 title, author가 중요하지만 옷은 size와 gender가 중요.
- cold start item
- Candidate retrieval challenge
- 유저와 아이템 임베딩을 같은 공간 상으로 보내야한다는점
- Recalld을 높혀야한다는 점
- Ranking challenge
- Re-ranking을 통해 topk 성능을 높혀야 한다는 점
Our Contributions
일반적으로 two-tower 모델을 사용하며, 유저 인코더와 아이템 인코더 2개의 파트로 분리되어있음
그런데, 유저 인코더 부분은 두가지 문제가 있음
- Single vector representation bottleneck: 유저 임베딩을 여러 임베딩 (Item interactions, profile)들을 하나나의 임베딩으로 합치는 데 생기는 bottleneck
- High infrastructure and maintenance costs: 유저 임베딩의 학습, 추론의 비용이 만만치 않다.
그래서, 다음과 같이 유저 인코더를 대신할 query encoder를 도입. query는 유저가 보거나 구매한 (클릭도 포함일듯) 아이템이며 item encoder에는 그다음 구매 아이템, 즉 타겟이 들어감. (query에도 구매가 들어가므로 타겟을 잘 설정해줘야할 것 같음)
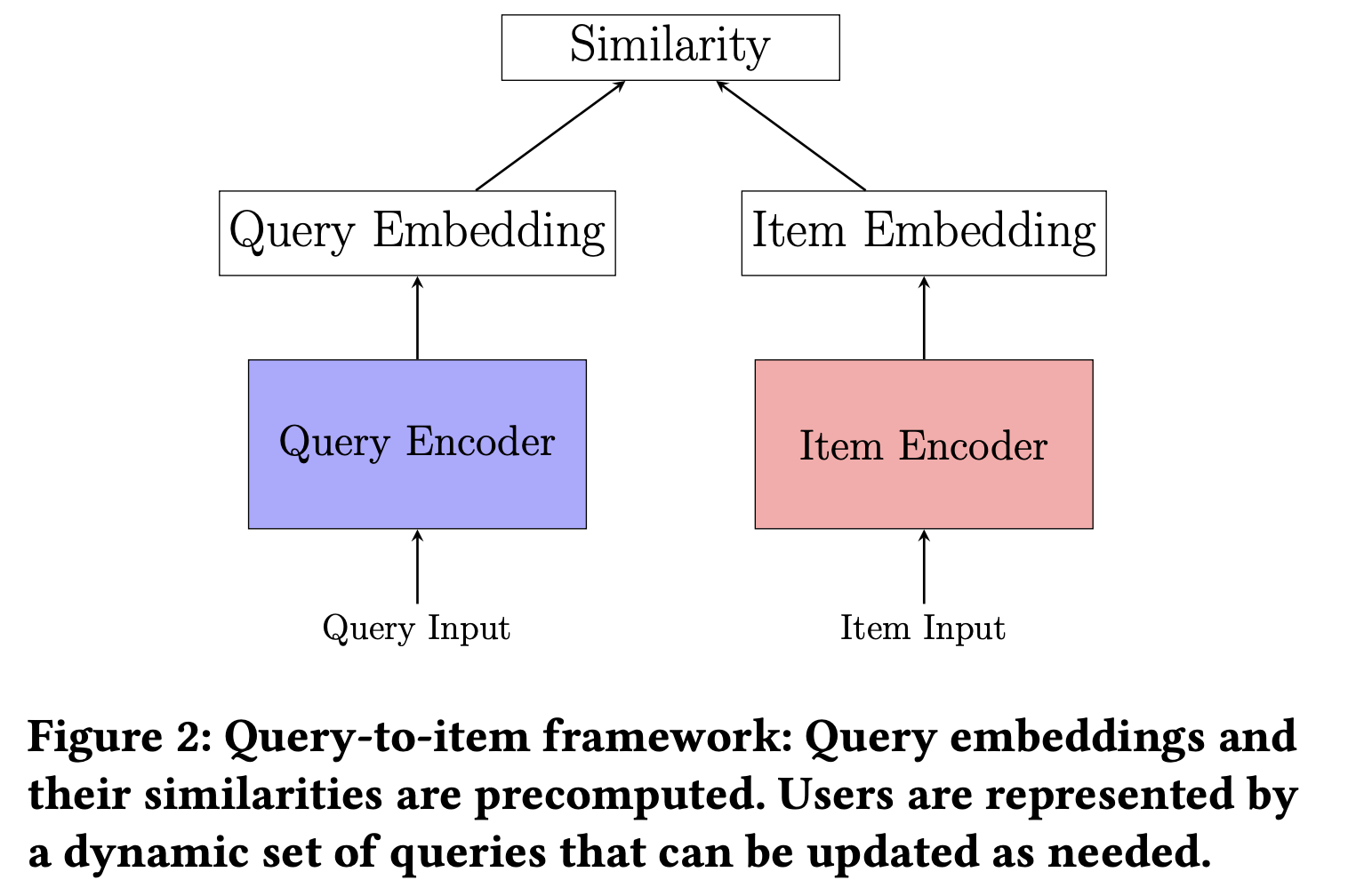
따라서, 이런 모델 구조를 가져감으로써 얻는 이득은 다음과 같다.
- 아이템 방면으로 유저, query embedding 을 만들기 때문에 학습, 추론에서 효율적이다
- query embedding을 2분 마다 업데이트 해주면서 실시간 피드 추천이 가능해짐
- 개인화 서비스 측면에서 서비스 품질을 높힘. 구매관련, 뉴스관련 컨텐츠들이 들어감.
Methology
Representing an Item with Three Embeddings
다음 세가지 role들이 있다는 가정하에 세가지 타입으로 item embedding을 표현함. 각 item에 맵핑되는 special token이 있음.
query 임베딩의 경우엔 relation이 들어감.
- View query: view-buy relationship 의미.
[Q_V]
- Buy query: buy-buy relationship, 어떤 물건을 사고난 다음 사는 상황
[Q_ B]
- Target item: view 혹은 buy queries 가 주어진 뒤에 사는 상품
[TGT]
하나의 모델에서 다음과 같이 3가지 타입의 $Q_i^v, Q_i^b, T_i$ 임베딩이 추출되는데 이 방법을 Single Input Multi Output (SIMO) 임베딩 모듈이라 정의함.
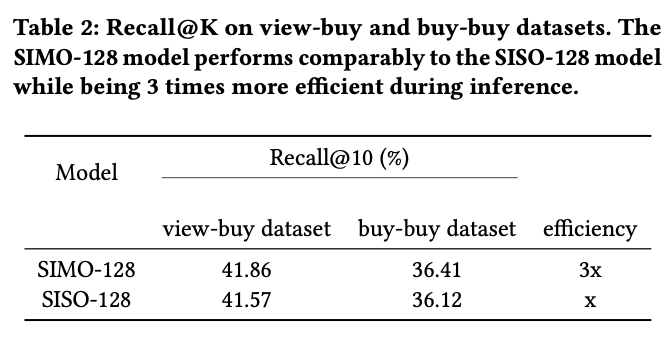
하나의 모델(One Model)의 Run으로 3가지 타입의 임베딩을 한번에 추출하는게 SISO(Single Input and Single Output) 보다 3배 효율이 좋음
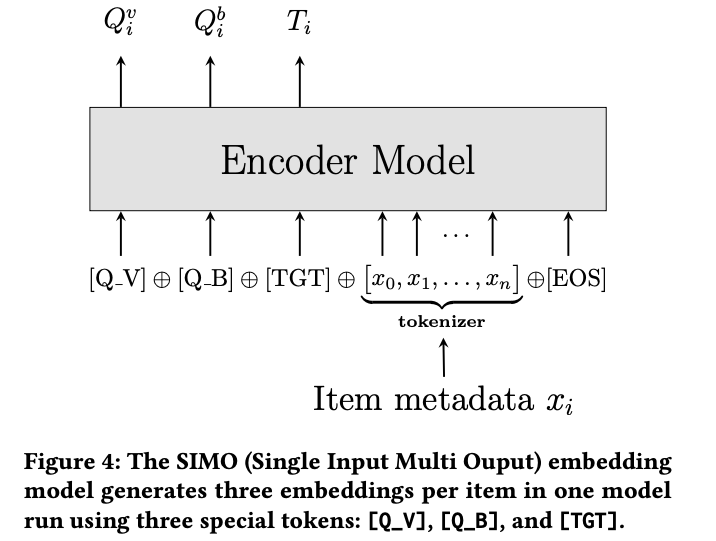
Overview
전체적으로 2 phase로 나뉨.
하나의 모델에서 3가지 임베딩이 추출되는데 이 방법을 Single Input Multi Output (SIMO) 임베딩 모듈이라 정의함.
Training with Contrastive Learning
query부는 view-buy, buy-buy 2가지 타입의 relationship이 있다. 따라서 다음과 같이 query, reationship, target 으로 training dataset을 표현.
$$
{ \left( q_i, r_i, t_i \right) }_{i=1}^N
$$
위에 제시된 data들은 positive 들이고, 이외에도 similarity를 학습하기위해서 negative 들을 다음 4가지 방법론들을 활용해 뽑는다. 실험에서 나중에 나오는데
- in-batch negative
- uniformed sampled negative
- mixed negative: in-batch와 uniform을 합친 방법 WWW'20
- self-negative
negative 샘플 반영은 false negative(query입장에서 볼때 잘못된 taget)와 false positive(query가 잘못되었을때 target) 상황이 있다(잘못된 상황을 tilde 로 표시). 따라서, 다음과 같이 softmax 계산 방향 측면에서 두 타입의 Loss로 표현됨.
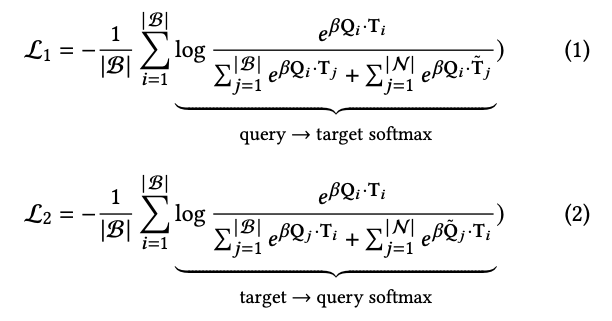
Inference
Precomupting embedding, Precomputing similarity, Generating pesonalized feeds 3번의 step 이 필요함.
-
Precomputing embedding: item마다 catalog 정보를 이용해서 3가지 타입(query로 사용될 경우 view-buy, buy-buy두가지 타입과 target 타입)의 embedding을 뽑아놓는다.
-
Precomputing similarity: FAISIS 를 이용하여 ANN에 사용할 vector기반의 indexing 정보를 구해놓는다.
-
Generating personalized feeds: daily 단위로 모든 고객의 query정보로 추천 결과를 생성하여 DB에 저장하고, 2분 단위로 active 유저의 query들에 대해 업데이트를 한다.
Experiments
Dataset
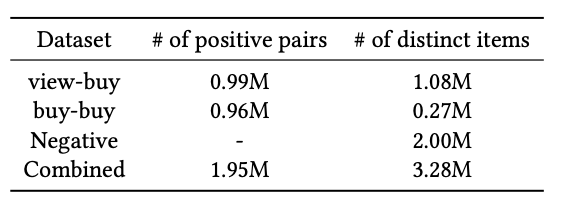
- view-buy dataset: 4개월 내 minimum occurrence 와 cosine metric threshold를 만족하는 view-buy relationship 들을 가져옴
- buy-buy dataset: 모든 buy-buy pair 중에 top 1M 만 사용. view-buy때와 마찬가지로 minimum rule이 적용.
- negative dataset: 2M 상품 에서 uniform sampling
Offline Evaluation
Pinterest에서 발표한 KDD'22 ItemSage 에 나온 대로 distractor set으로 사용할 1M의 아이템들을 샘플링하여 뽑고, recall@K 를 측정.
전체적인 performance는 SIMO가 SISO보다 약간 높았지만, 비슷하였다.
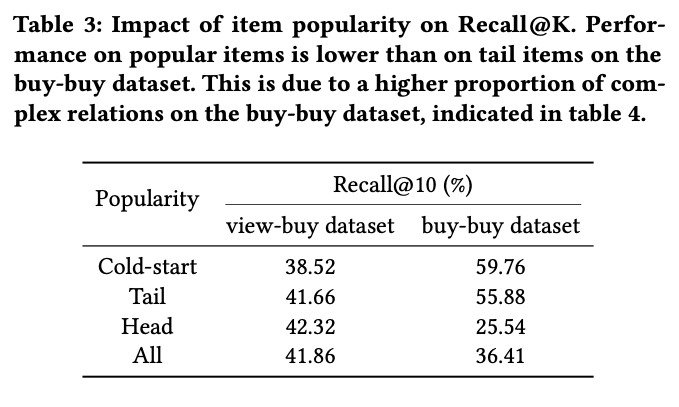
item의 popularity정도를 구간을 나눠 계산하였음. cold의 경우에 buy-buy 를 활용하였을떄 성능이 좋은 반면, head로 갈수록 view-buy를 활용하였을떄 성능이 좋았음.
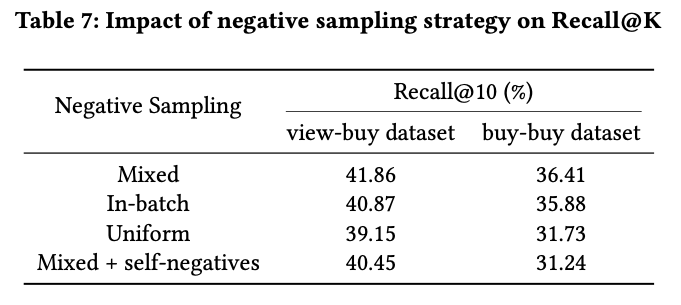
Negative sampling 전략의 경우 Mixed 방식에서 가장 성능이 우수하였음
Online A/B testing
conversion의 경우 5%, wish(찜)의 경우 27% 향상

Conclusion
- E-commerce의 실시간 feed 추천시스템 과정을 simple하게 잘 설명한 논문
- query에 대한 3가지 타입을 뽑는 모델링으로 Interpretabilty를 높힘
- SIMO모델로 한번의 encoding으로 query, target 아이템을 모두 뽑았기 때문에 성능은 크게 올리진 못했지만 Computation efficiency를 높힘