발표 영상은 다음과 같음. 싱가폴의 A* 연구기관에서 발표.
[SIGIR'24] PO4ISR: Large Language Models for Intent-Driven Session Recommendations, Zhu Sun et al
Motivation & Contribution
전통적인 세션 기반 추천 시스템 대비 사용자 의도를 더 잘 이해하기 위해 LLM도입. 다른 session 기반 LLM 의 fine-tuning 측면에서 Prompt로 session마다 다른 추천결과를 만들어내는 ISR approach 를 제안. ISR(Intent-driven Session-based Recommendation)은 다음 두가지 방면으로 이점이 있음.
- Prompt-Oriented LLM Integration: 세션데이터를 Prompt로 변환하여 LLM에 입력으로 넣어줌으로서 더 확장된 context정보를 주어 성능 향상에 기여하고자 함.
- Intent-Centric Adaptability: Prompt가 실시간으로 입력되기 때문에 변화에 즉각적으로 맞춤형 추천을 제공.
결과적으로 session 기반 추천 task에서 Prompt-tuning 기반의 LLM구조를 활용해 intent를 얻는 구조를 사용해 실시간 적응성과 의도 표현의 유연성을 갖춘 것이 가장 큰 차별점.
PO4ISR은 Prompt Optimization for ISR 의미. 본 논문은 PO4ISR를 사용해 다음과 같은 효과들이 보였음.
- session마다 다른 결과와 성능 우위
- generalized performance 증가. 즉, cross domain으로 사용했을 때 좋은 효과
- 적은 데이터로도 좋은 성능
Related Wroks
SR -> ISR -> LLM-based SR 순으로 발전.
ISR 연구에서는 Transformer/GNN 기반 방식이 성행하였는데, 모든 세션의 uniform하고 의도가 제한적이라는 단점이 이었음. 이런 단점을 극복하기 위해 LLM이 사용됨. 근래 ICR을 이용해 LLM-based SR의 성능을 높히는 연구들이 있었고 성능이 좋았음. 하지만 선행 연구들은 세션 내 intetion의 변화에 집중하진 않았었고 본 논문에서 LLM-based ISR 방식을 제안하는 것이라 함.
참고: zero-shot prompt를 SR에서 처음 사용한 추천 논문: NIR code
The Proposed Method
본 논문의 overall architecture는 PO4ISR은 다음과 같은 형태임. 각 데이터셋 에 대해 한번의 업데이트 마다 여러 단계의 Prompt가 만들어지고, 최적화된 prompt를 찾고자 함.
LLM이 학습되는것이 아니라 추천 task 를 위한 최적화된 prompt를 찾는 방법임.
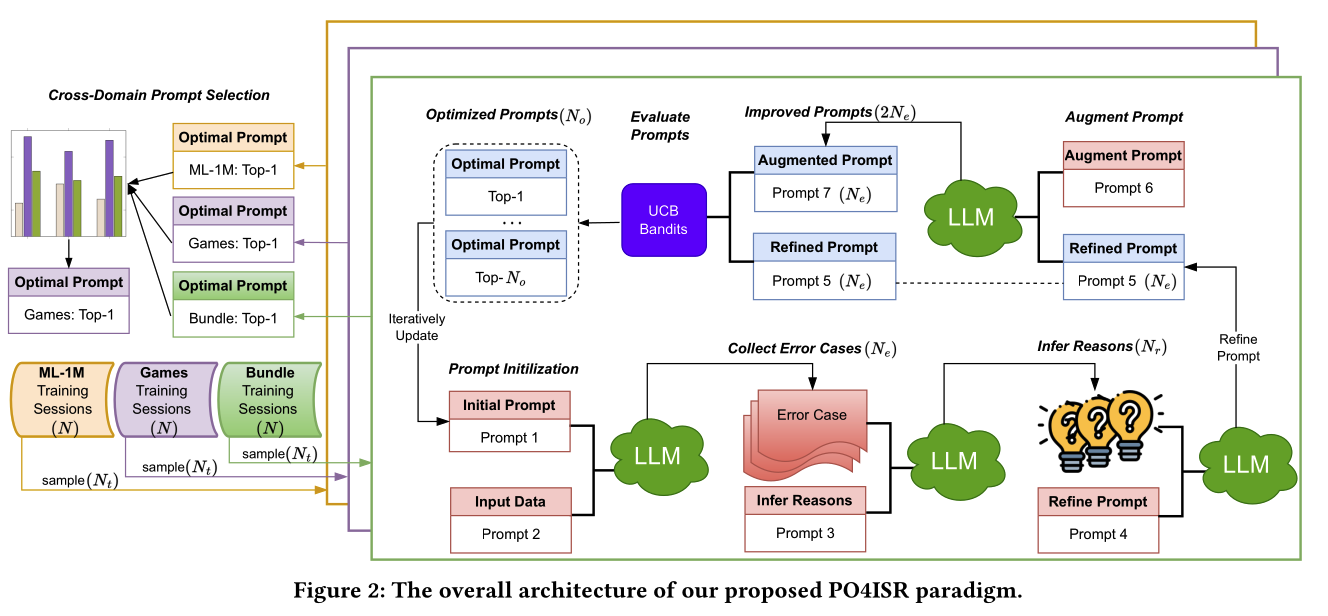
위의 과정에서 각 단계별 prompt의 구체적인 지시문은 논문에 적혀있어서 이를 참고.
간략하게 설명하면, prompt initialization, optimization, selection 단계로 구분지어 설명할 수 있다. (Prompt 별로 설명하는 것보다 깔끔)
- PromptIint: 유저 history를 기반으로 $N_t$ 개의 candidation set과 target 를 만들고, 이를 prompt를 이용해 맞추도록 한다.
- PromptOpt: PromptInit에서 맞추지못한 error case $N_e$ 개를 가져와 맞추지못한 reason text $N_r$ 개를 만들고, promp4에서 기존 prompt에서 수정된 refined prompt를 만들면 각 refine prompt마다 변형된 augment prompt를 만들어 총 2$N_e$개의 prompt 후보가 생김. 이들 중 UCB Bandit으로 top $N_o$ 개의 최적화된 prompt 리스트를 reward기반으로 뽑음.
- PromptSel: cross domain 측면에서 모든 데이터셋(여기서 3개)과 $N_o$ 개의 prompt 중에 성능이 우수한 prompt를 선택함. 위의 예시에선 Games 의 top-1 prompt 를 택.
따라서, 다음과 같은 알고리즘 형태로 prompt의 Optimization이 수행 됨.

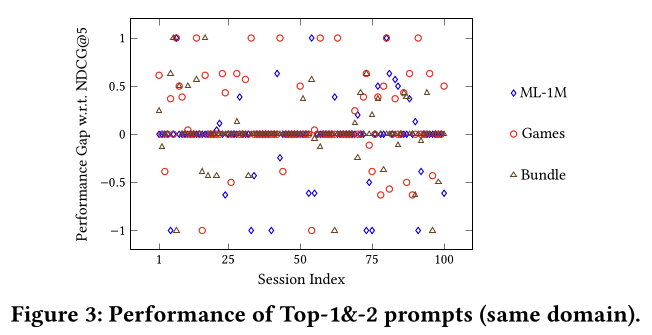
PromptSel 에 대해 왜 굳이 UCB로 $N_o$개의 Prompt를 골랐는지 의문이 들 수 있는데 다음과 같이 top-1, 2의 prompt 의 성능 차이를 보았을때 top-2의 prompt 가 더 좋은 성능을 가져올 수 있기 때문이라고 함.
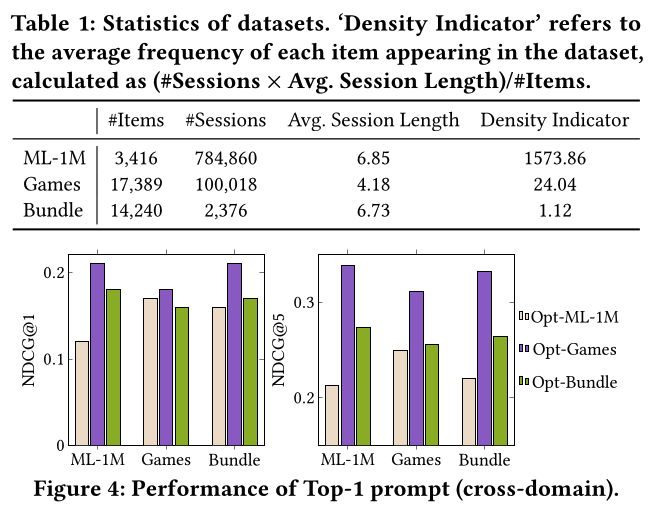
그래서, prompt의 generalization performance를 측정해보기 위해 cross domain task를 수행 해보았는데 각 데이터 셋에서 Games의 top-1 prompt로 다른 domain까지 사용해 결과를 보았을때 가장 좋게 결과가 나옴. 그런데, 이게 top-1이 성능 높은걸로 봐서는 top $N_o$ 까지 중 다른 prompt 로는 좋은 결과가 도출되지 않았던 걸로 생각이 되긴 함.
Experiments
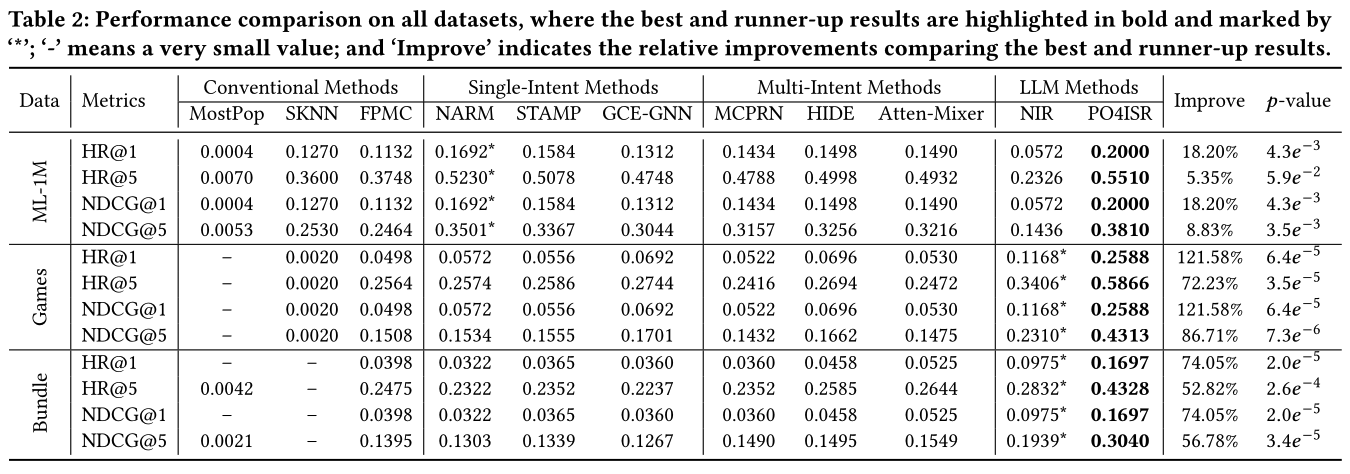
conventional 방법, ISR 방법 대비 LLM-based ISR 성능인 POS4ISR에서 성능이 크게 향상됨.
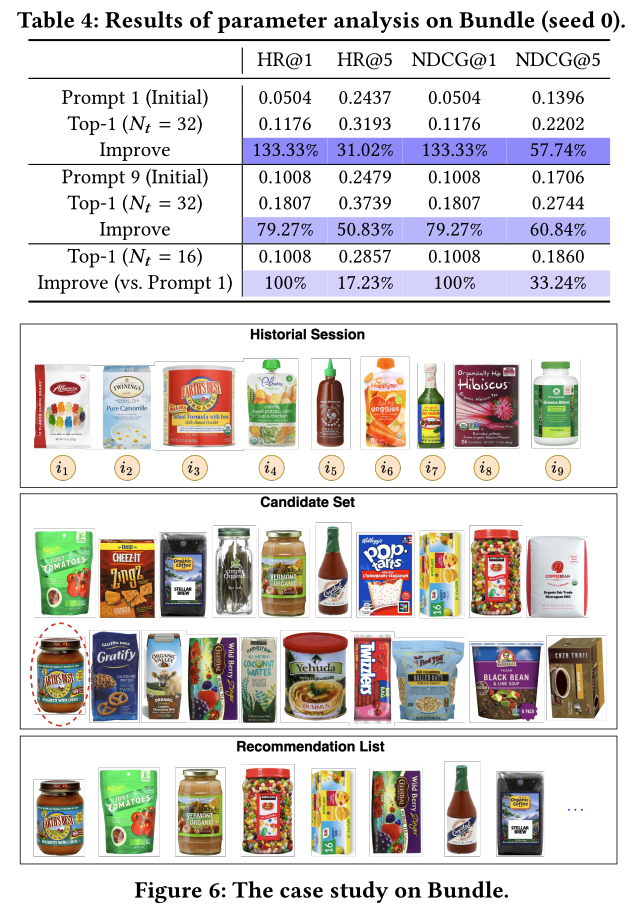
정성적으로 다음과 같이 여러 intention 이 섞여있는 경우에 대한 evaluation 예시를 보임. 상품의 intention을 [1, 2, 8], [3, 4, 6], [5, 7], [9] 로 나눠 생각해볼 수 있음.
개인 견해
LLM으로 SR 에서 prompt-tuning을 통해 Intention을 파악해 성능을 높히는 방안을 체계화 시킨 논문. 그런데 전체 architecture를 보면 직렬로 너무 복잡한 prompt 를 만들도록 되어 있는 구조 여서 Industry에서 크게 와닿지 않을 것 같음. 데이터셋 들도 2만개 아래 상품들이고 candidate set이 20개중 top 1을 맞춰내는 task로 설계 되어있다. 다만 특정한 상황(할인 상품이라던지, 이벤트성 상품들 제한)에서 추천 pool이 적은 상황이고 explainablity가 높은 추천 스펙이 요구될때에는 쓸 수는 있을 것 같음. 하지만 prompt를 여러개 만들어 관리하는 구조는 크게 이점이 없어 보여서 리소스 측면에서 이득일 것 같음.