[CIKM'23] Meta-Learning with Adaptive Weighted Loss for Imbalanced Cold-Start Recommendation
Motivation & Contribution
MAML 방법을 적용할때 SR의 데이터셋은 불균형이 심각해 최적화하기 어려운데 이를 보정하기 위한 방법을 제시한 논문.
처음으로 SR 에서 MAML를 적용할떄 imbalance 문제를 다룬 논문임이 강조됨.
유저들의 rating은 개개인 마다 다음 그림(a)의 분포처럼 imbalance 한 형태를 띄고있음. 그래서 (b)와 같이 MAML 접근을 통해 inner-loop adapation을 할 경우 major class 에 대해 overfitting 될 수 있음.
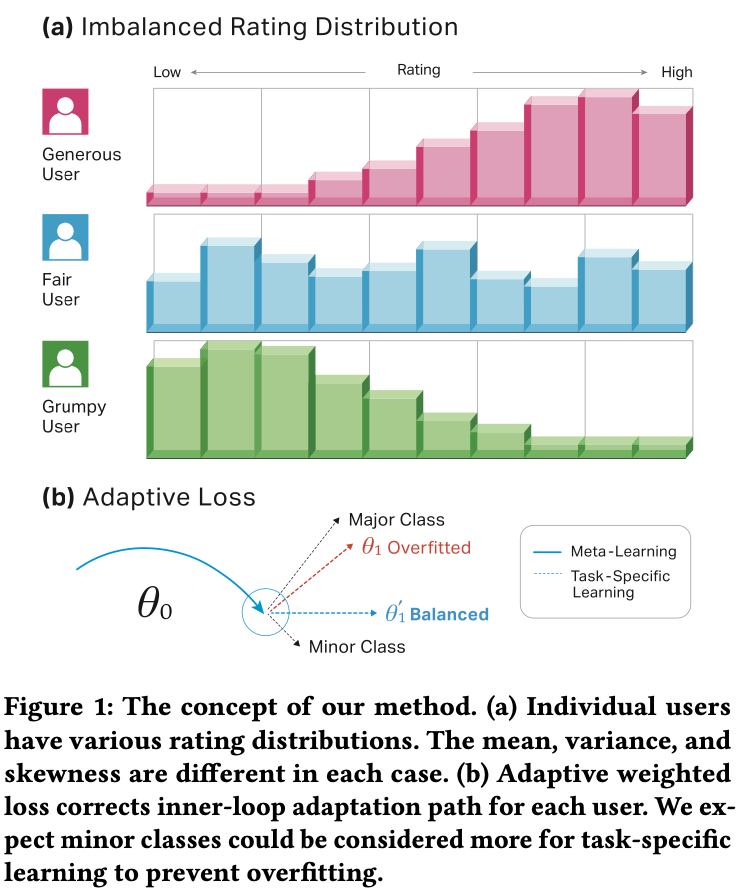
또한 SR 데이터는 𝑁 -way 𝑘 -shot setting이 보장되지 않고 variable length 형태임.
Related Work
SR에 대해 MAML로 접근하는 방법들은 꽤 많았음. 그리고 meta-learning에서 imbalance를 다룬 논문도 많았음.
하지만, imbalance 를 보정하기 위해 복잡한 네트워크 연산이 들어가는 loss term 이 들어간다던지 어려운 알고리즘들을 사용 하는것 보다 직관적이고 자동화된 방법을 제시함.
중요한건 sequential 방면에서 접근한 방법이 없었음.
Problem Formulation
SR 의 regression task 로 생각하면 됨. 유저의 rating history가 주어질때 그다음 rating 예측 정확도를 높히는게 목표. (SASRec과 같은 논문에선 classification task 였음)
Methology
overview를 보면 MAML의 bi-level optimization 형태를 기본적으로 갖추고 있으며 imbalance를 보정하기 위한 adaptive weighted loss가 task adaptation 단계에서 계된됨.
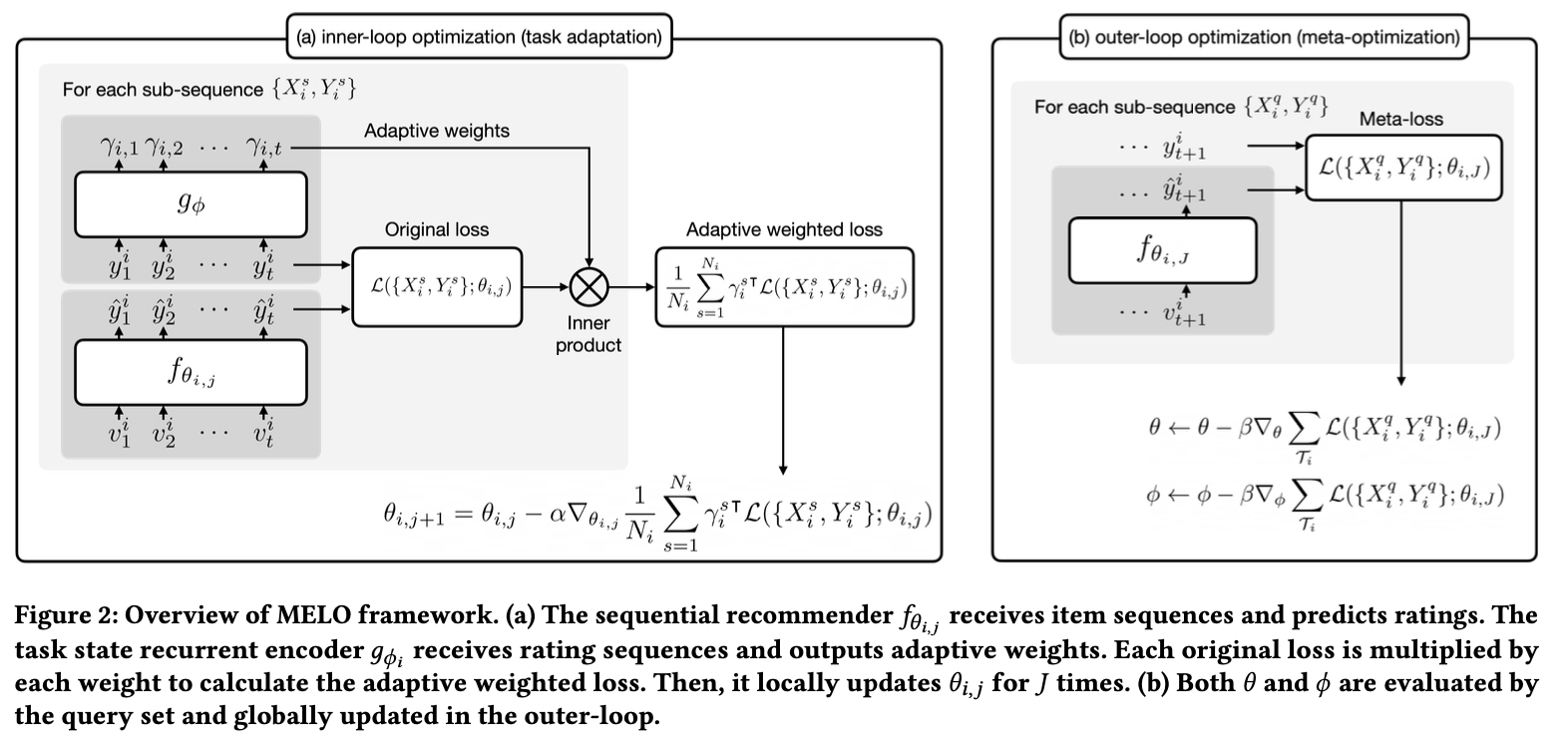
adaptive weighted loss 는 위의 그림에 보이듯, rating sequence를 입력으로 넣어 $g_{\phi}$ 로 출력된 adaptive weight values $\gamma_{i}^{s}$ 로 original loss를 weight sum한 결과다.
따라서, MELO 는 다음과 같이 학습됨. MAML 방식과 차이점은 $\gamma_{i}^{s}$ 가 추가되었다는 점을 보면 됨.

Experiment
데이터 셋은 다음과 같으며, balance score를 계산해놓음.
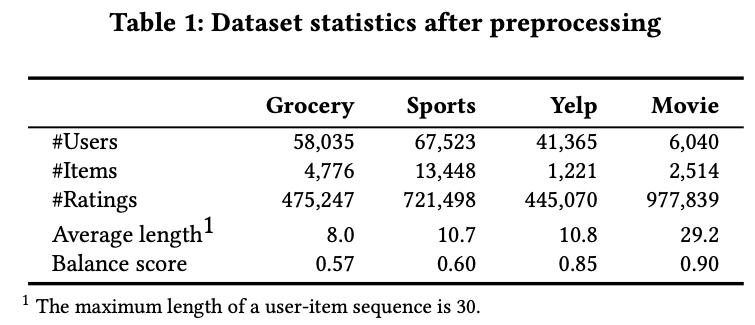
movielensd 의 경우 균등한 편이여서 그런지 성능이 MELO를 적용하지 않았을 떄가 더 좋은 경우도 있다.
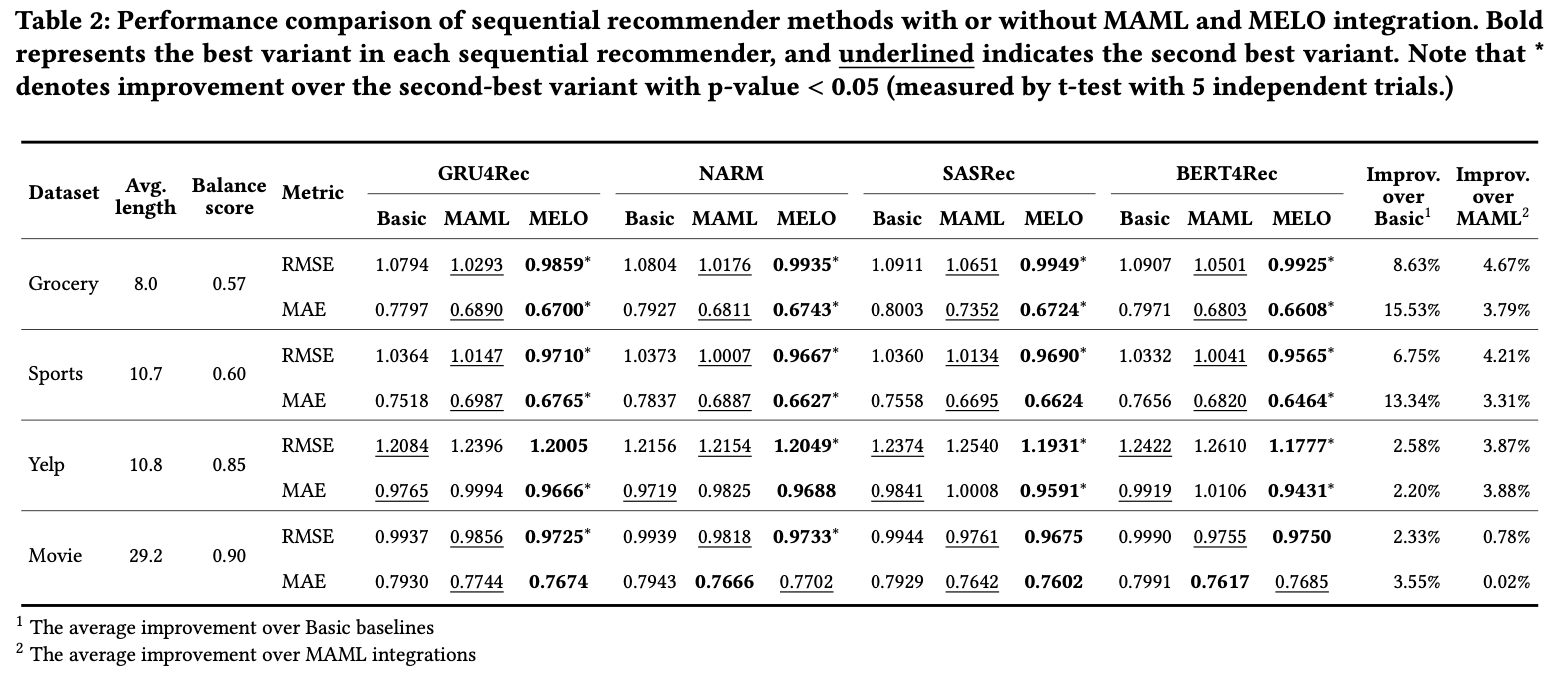
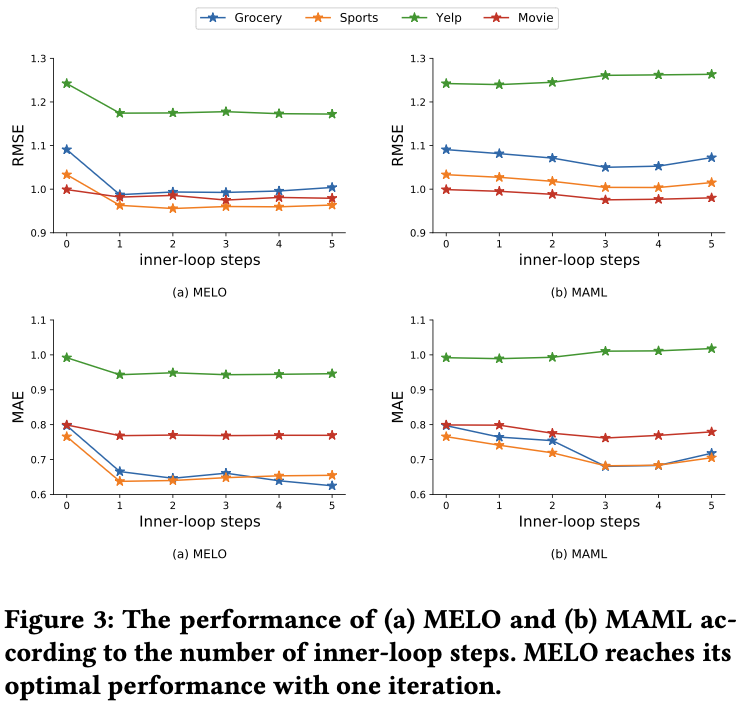
MELO 말고 다른 보정 방인 Focal, Stats 보다 좋은 결과.
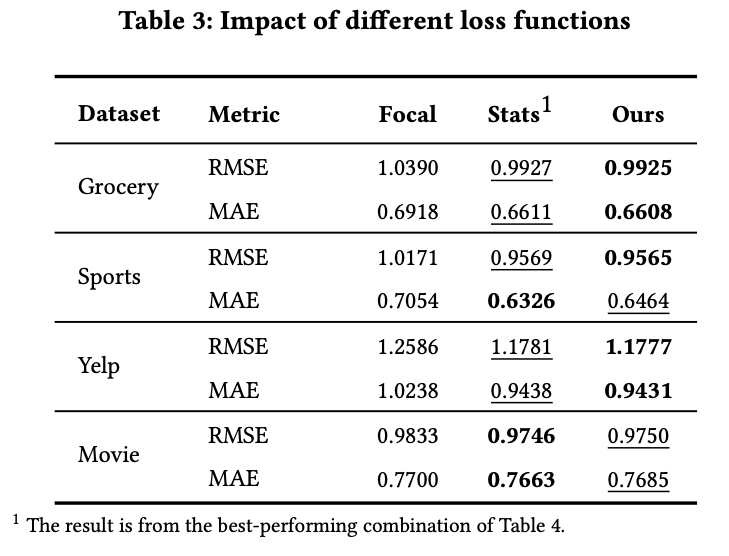
MELO 방법이 inner-loop를 한두번만 돌아도 성능이 MAML 대비 좋다는걸 보였고,
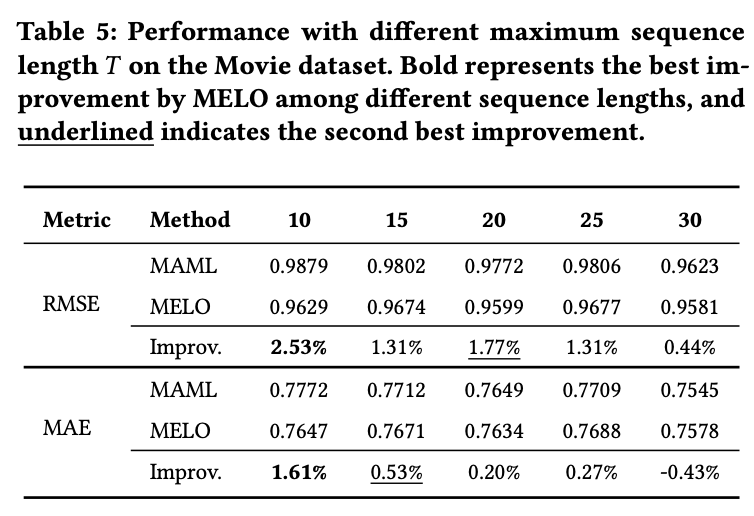
sequence가 짧은 경우에도 좋다고 함.
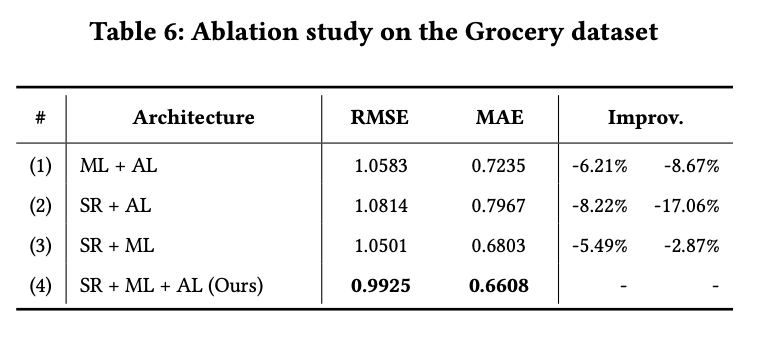
왜 SR을 써야하며, 왜 SR에다 MAML을 쓰는게 좋고 Imbalance 보정도 좋은지 ablation study로 다음과 같이 보임.
개인 견해
논문에서 제안한 모듈은 단순히 SR에서 MAML 을 적용한 선행연구에서 regresstion task 형태로 바꿔 task adaptation단계에서 히스토리 평점에 대한 weight로 보정할 네트워크 하나를 추가로 넣어준게 끝인것 같음. 처음으로 imbalance 문제를 다룬게 정말 큰 advantage로 작용한게 아닌가 싶음. 성능도 unbalance 한 데이터가 아니면(movielens 경우) 보정해 주지 않았을 떄 대비 안좋은 상황도 있다.
이 방법의 장점은 여러 sequential baseline 로직들을 쉽게 비교할 수있어서 오히려 참고시엔 도움이 될것 같다. 하지만, ranking metric 이 측정되지 않은 건 의문이 있음.
오픈된 코드는 깔끔한 편이라서 리뷰해봐도 좋을듯