https://catboost.ai/ 를 써보자.
[NIPS'17] CatBoost: gradient boosting with categorical features support 논문에 게제된 알고리즘이다.
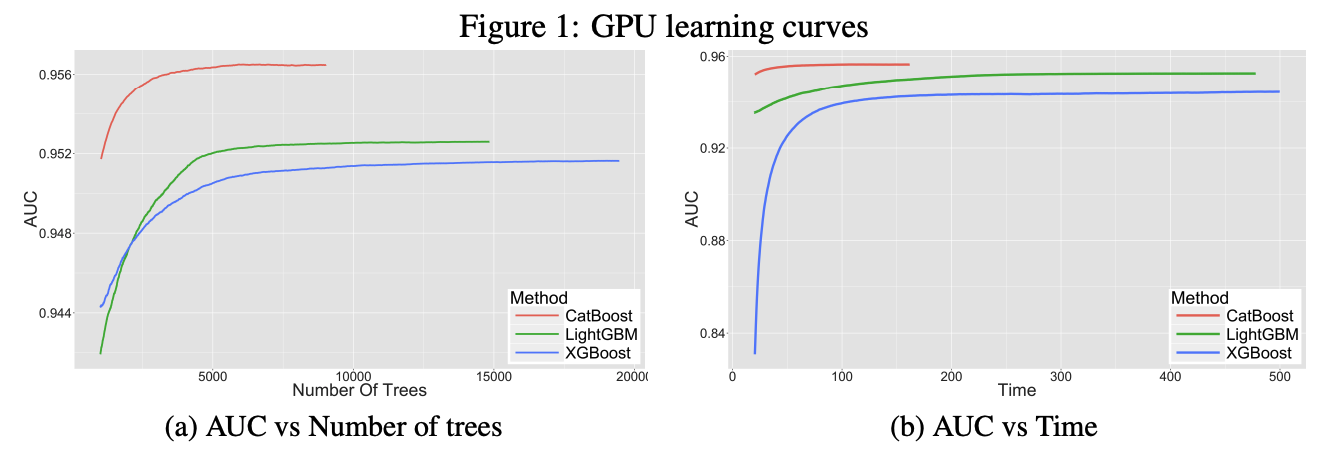
특히, 카테고리 feature가 많은 데이터의 경우 miscrosft의 LightGBM보다 더 성능, 속도가 우수한것으로 알려져 있음.
아래 튜토리얼을 보고 따라해본뒤 정리 예정.
https://github.com/catboost/catboost/blob/master/catboost/tutorials/ranking/ranking_tutorial.ipynb
리뷰후 내용 요약하면 다음과 같다.
MSLR https://www.microsoft.com/en-us/research/project/mslr/ 데이터셋은 bing(검색엔진)에서 query별로 document 의 relevance가 할당되어있다.
query별로document의 136개의 feature로 relevance값을 예측하는 task이다.
catboost 를 사용하면 다음과 같이 Pool을 만들고, fit_model로 target_loss(여기선 RMSE)를 지정해주고 학습하면
from catboost import CatBoostRanker, Pool
def fit_model(loss_function, additional_params=None, train_pool=train, test_pool=test):
parameters = deepcopy(default_parameters)
parameters['loss_function'] = loss_function
parameters['train_dir'] = loss_function
if additional_params is not None:
parameters.update(additional_params)
model = CatBoostRanker(**parameters)
model.fit(train_pool, eval_set=test_pool, plot=True)
return model
def create_weights(queries):
query_set = np.unique(queries)
query_weights = np.random.uniform(size=query_set.shape[0])
weights = np.zeros(shape=queries.shape)
for i, query_id in enumerate(query_set):
weights[queries == query_id] = query_weights[i]
return weights
train_with_weights = Pool(
data=X_train,
label=y_train,
group_weight=create_weights(queries_train),
group_id=queries_train
)
test_with_weights = Pool(
data=X_test,
label=y_test,
group_weight=create_weights(queries_test),
group_id=queries_test
)
fit_model(
'RMSE',
additional_params={'train_dir': 'RMSE_weigths'},
train_pool=train_with_weights,
test_pool=test_with_weights
)
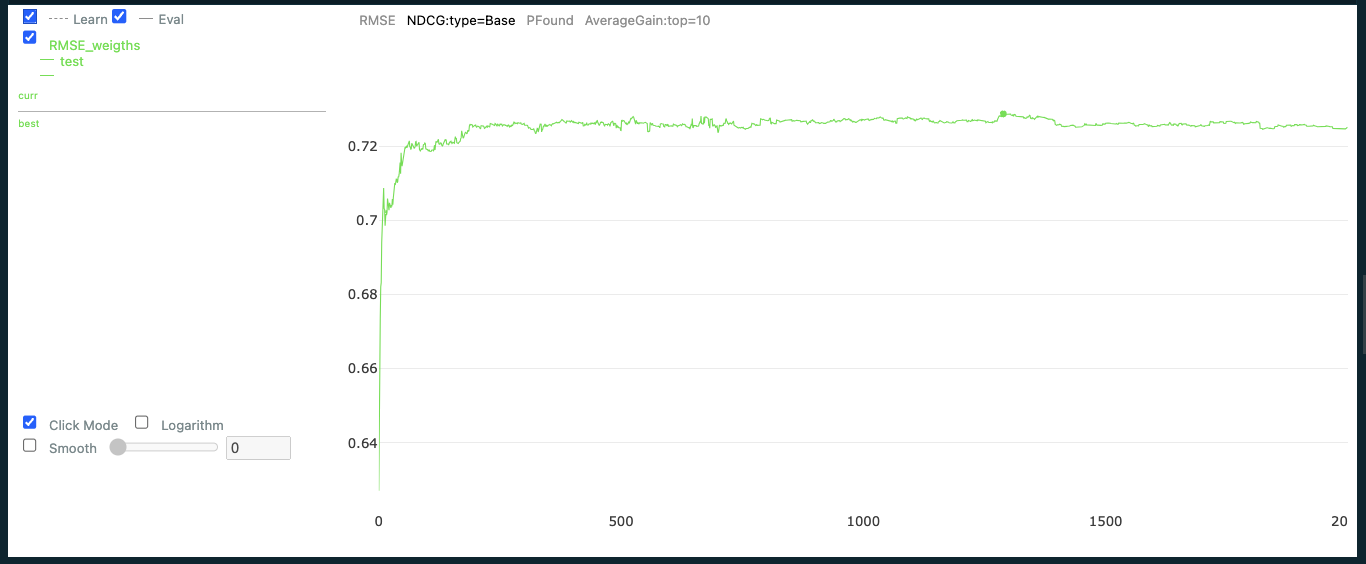
다음과 같이 Visualize된다. RMSE, NDCG 등 선택 가능하다.
GPU도 쓸 수 있고 유용한 tool 인 것 같다.