[SIGIR'24] SeRALM:Enhancing Sequential Recommenders with Augmented Knowledge from Aligned Large Language Models
알릴바바의 계열사인 Ant 그룹에서 발표한 논문.
Motivation & Contribution
어떤 계열의 모델이든 상관없이 LLM 의 textual knowlege를 ID-based SR에 align시키는 model-agnostic 방법을 제안한 논문. 이외에 본 논문의 추가적인 특징은 다음과 같다.
- Item에 대한 knowledge를 추출하는 효율적인 Prompt 제안
- SR 과 LLM 이 서로 얽혀 병합된 형태의 architecture로 alignment training 하는 방법을 제안
- LLM 을 align 하기 위해 fine-tuning, inference 과정에서 delay를 줄이기 위한 효율적인 asynchronous technique 제안, 즉 LLM 추론 속도가 늦어지는데서 오는 한계를 최대한 없애는 방향으로 구조를 설계 (industry관점에서 참고)
Related works (기존 연구와의 차별점)
기존 LLM 기반의 추천 연구 트렌드는 prompting, in-context learning, instruction tuning 을 기반으로 LLM 을 추천 task에 align 시키는 방법들이 주를 이뤄왔음. 대표적으로 LLaMA 를 기반으로한 TALLRec, GenRec 등이 있음. 이 방법들이 SR 방법대비 압도하지는 못했기 때문에 MIM과 BPR을 동시에 최적화하는 방식을 제안했다는 점을 강조.
개인의견: 내가 생각하기에 기존 연구대비 차별점이 뚜렷하지는 않아서 weak point라고 생각함.
Methodology
제안된 방법의 overall architecture는 다음과 같음. 2단계로 나뉘며 1,2 단계 사이의 피드백으로 LLM을 fine-tuning(본 논문에서는 alignment training으로 불리움)시키는 구조.
먼저, item 마다 prompt 으로 구한 LLM의 응답을 추가적으로 사용해 textual knowledge를 얻고, SR task를 수행하며 얻은 피드백으로 LLM을 align시키는 형태임.
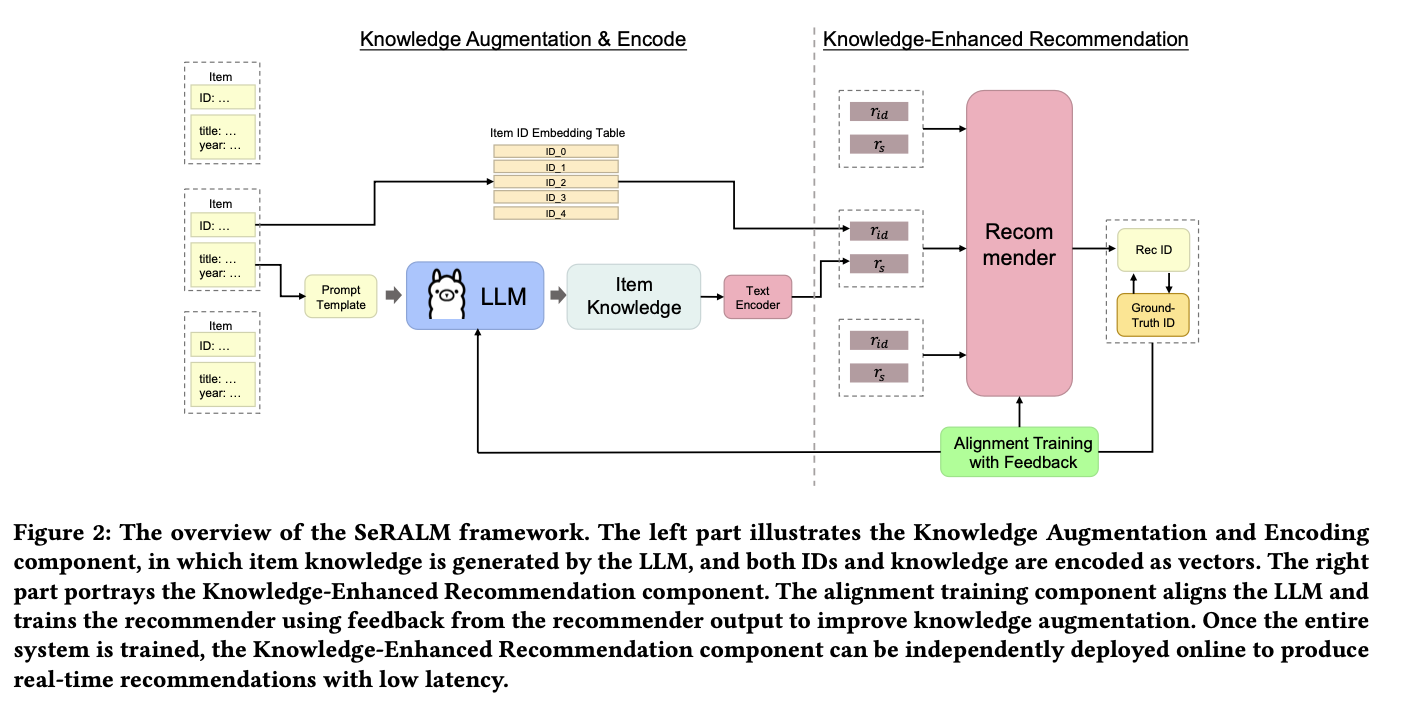
Knolwege Augmentation
저자를 Prompt 를 다음과 같이 설계하여 Item에 내재된 textual knowledge를 활용하고자 함. summarization에 이 영화를 좋아하는 유저에 일반적인 특성을 뽑아 냄. 뽑힌 텍스트 정보는 BERT(굳이 학습하지 않고 freezed 된 것으로 보임) 같은 encoder로 벡터화 시켜서 얻은 $r_s$ 사용.

Enhanced Recommendation with Augmented Knowledge 부는 일반적인 SR 과 다를게 없어서 설명 생략
Alignment Training
다음 알고리즘 형태로 업데이트 됨.

Recommender 업데이트 수식
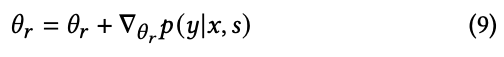
LLM 업데이트 수식 은 over-optimization(과적합)을 줄이기 위해 KL divergence term을 추가함.

여기서 $L_{KL}$은 다음과 같다.
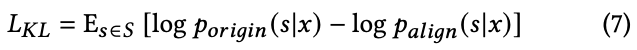
참고로 $\nabla_{\theta_l} L$ 는 다음과 같이 계산 됨. 마지막은 monte-carlo estimate가 사용됨.
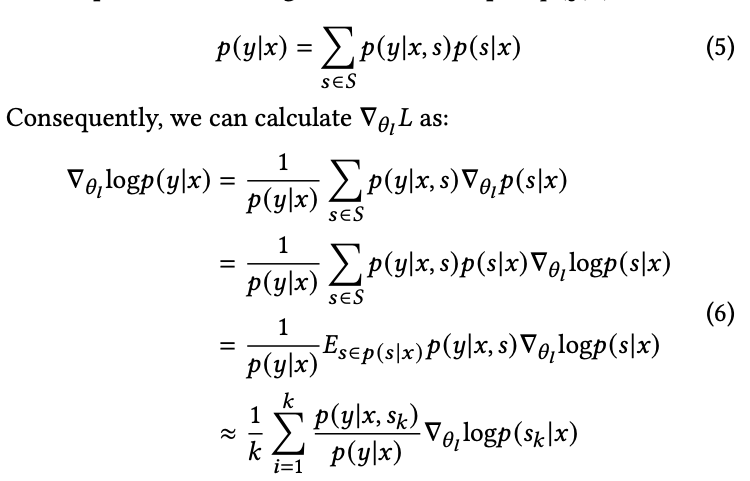
Asynchronous generation during training
Alignment Training의 과정은 Asynchronous하게 다음 두개의 별개 job으로 구현될 수 있음. 실 배포 시 Inference전에 $r_s$ 가 이미 generator에 의해 생성되어 있기 떄문에 delay가 생기지 않게 됨. (모델링으로 delay를 줄인계 아니라 asynchronous 한 시스템 구조로 부터 얻는 이득임)
- trainer job: 모델 $\theta_r, \theta_l$ 을 업데이트
- generator job: item에 대한 textual knowlege $s$ 생성. 이때 모델은 최대한 최신 모델 사용. 단 LLM 업데이트는 너무 자주 이뤄지지 않도록(성능저하가 있따고 함) $N$ 번 업데이트 될떄마다 수행.

본 논문에서 Equation 8 에 대한 해석을 좀더 디테일하게 하였는데, textual knoowleng가 $y$ 예측에 미치는 영향력을 분석하였음.

개인견해: 그런데, textual knowlege 유무가 성능에 항상 도움이 되는가에 대한 증명은 아니라 약간은 애매한 증명 임.
Experiments
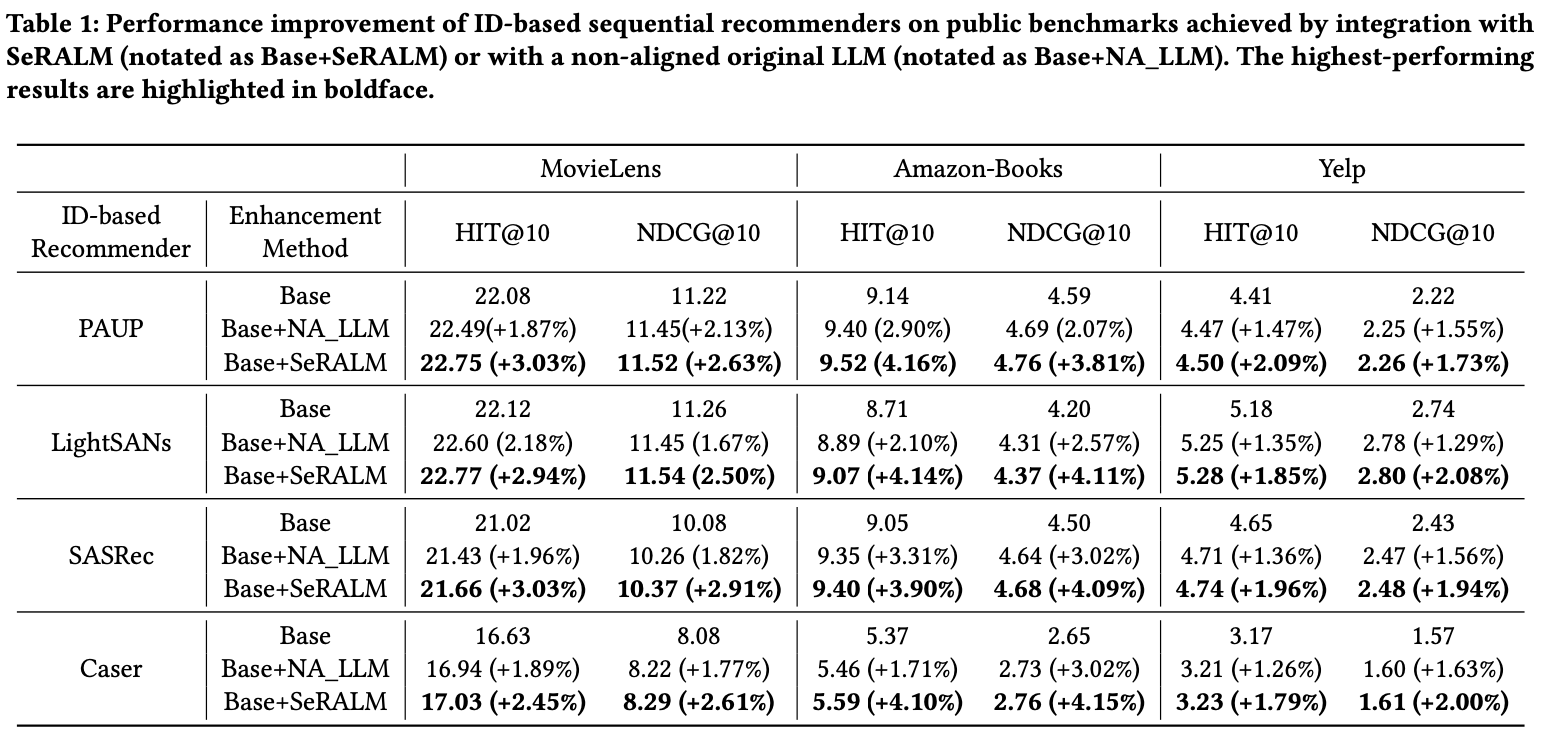
실험 결과를 보면, ID-based SR 대비 prompt-engineering 으로 textual knowlege만 추가(NA_LLM)해도 성능이 다 올랐고, alignment training으로 학습시키면 최대 향상을 이루어짐.
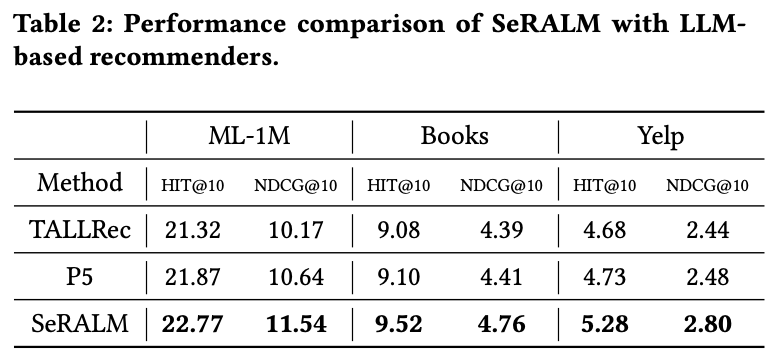
다른 LLM 기반 모델들에 비해서도 성능 우위.
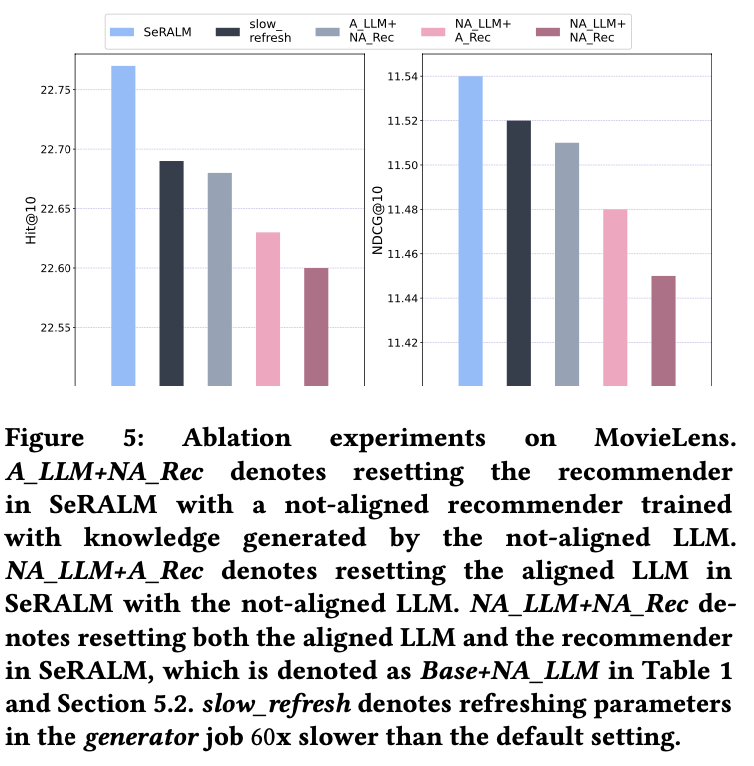
Ablation Study 결과로 LLM, RS 에 대해 각각 align 하지 않도록 하면 4가지 경우가 생기는데 성능이 점진적으로 align 하는게 도움이 되는 쪽으로 나옴.
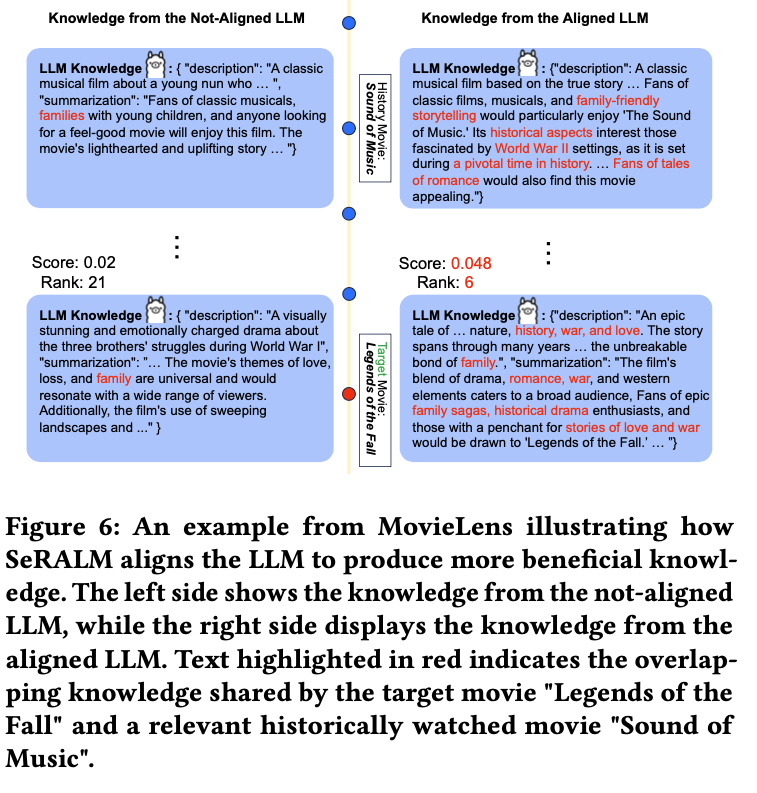
성능이 좋아시는 경우 어떤 경우인가 Case-study를 보면 다음과 같이 더 도움이 되는 방향으로 description이 생성된 것을 알 수 있음.
이 외에도 데이터가 더 희박한 상황에서 다른 LLM 기반 RS 성능 대비 우위를 보인다는 점. latency가 asynchrous 하게 분리시켜 사용하면 더 적다는 지 등의 내용이 어필 됨.
개인 견해
textual knowlege를 쉽게 사용 하는 방법중 하나로 생각되며 기업에서 쓴 논문인 만큼 Industry 관점에서 효율적인 시스템 구조를 제안한 것은 참고할만한 부분으로 보임. 논문에서 실험적인 성능 우위를 다방면으로 분석하였지만 이론적으로 확실히 우위를 보인다는 점은 보이지 못한 부분은 아쉬움. (결정적으로 오픈된 코드는 없음..)